

Wondering why some of your pages don’t show up in Google?
Crawlability problems could be the culprit.
In this guide, we’ll cover what crawlability problems are, how they affect SEO, and how to fix them.
Let’s get started.
What Are Crawlability Problems?
Crawlability problems are issues that prevent search engines from accessing your website pages.
When search engines such as Google crawl your site, they use automated bots to read and analyze your pages.

If there are crawlability problems, these bots may encounter obstacles that hinder their ability to properly access your pages.
Common crawlability problems include:
- Nofollow links
- Redirect loops
- Bad site structure
- Slow site speed
How Do Crawlability Issues Affect SEO?
Crawlability problems can drastically affect your SEO game.
Search engines act like explorers when they crawl your website, trying to find as much content as possible.
But if your site has crawlability problems, some (or all) pages are practically invisible to search engines.
They can’t find them. Which means they can’t index them—i.e., save them to display in search results.

This means loss of potential search engine (organic) traffic and conversions.
Your pages must be both crawable and indexable in order to rank in search engines.
11 Crawlability Problems & How to Fix Them
1. Pages Blocked In Robots.txt
Search engines first look at your robots.txt file. This tells them which pages they can and cannot crawl.
If your robots.txt file looks like this, it means your entire website is blocked from crawling:
User-agent: *
Disallow: /
Fixing this problem is simple. Replace the “disallow” directive with “allow.” Which should allow search engines to access your entire website.
User-agent: *
Allow: /
In other cases, only certain pages or sections are blocked. For instance:
User-agent: *
Disallow: /products/
Here, all the pages in the “products” subfolder are blocked from crawling.
Solve this problem by removing the subfolder or page specified. Search engines ignore the empty “disallow” directive.
User-agent: *
Disallow:
Alternatively, you could use the “allow” directive instead of “disallow” to instruct search engines to crawl your entire site. Like this:
User-agent: *
Allow: /
Note: It’s common practice to block certain pages in your robots.txt that you don’t want to rank in search engines, such as admin and “thank you” pages. It’s a crawlability problem only when you block pages meant to be visible in search results.
2. Nofollow Links
The nofollow tag tells search engines not to crawl the links on a webpage.
The tag looks like this:
<meta name="robots" content="nofollow">
If this tag is present on your pages, the links within may not generally get crawled.
This creates crawlability problems on your site.
Scan your website with Semrush’s Site Audit tool to check for nofollow links.
Open the tool, enter your website, and click “Start Audit.”

The “Site Audit Settings” window will appear.

From here, configure the basic settings and click “Start Site Audit.”
Once the audit is complete, navigate to the “Issues” tab and search for “nofollow.”
To see whether there are nofollow links detected on your site.

If nofollow links are detected, click “XXX outgoing internal links contain nofollow attribute” to view a list of pages that have a nofollow tag.

Review the pages and remove the nofollow tags if they shouldn’t be there.
3. Bad Site Architecture
Site architecture is how your pages are organized.
A robust site architecture ensures every page is just a few clicks away from the homepage and there are no orphan pages (i.e., pages with no internal links pointing to them). Sites with strong site architecture ensure search engines can easily access all pages.

Bad site site architecture can create crawlability issues. Notice the example site structure depicted below. It has orphan pages.

There is no linked path for search engines to access those pages from the homepage. So they may go unnoticed when search engines crawl the site.
The solution is straightforward: Create a site structure that logically organizes your pages in a hierarchy with internal links.
Like this:

In the example above, the homepage links to categories, which then link to individual pages on your site.
And provide a clear path for crawlers to find all your pages.
4. Lack of Internal Links
Pages without internal links can create crawlability problems.
Search engines will have trouble discovering those pages.
Identify your orphan pages. And add internal links to them to avoid crawlability issues.
Find orphan pages using Semrush’s Site Audit tool.
Configure the tool to run your first audit.
Once the audit is complete complete, go to the “Issues” tab and search for “orphan.”
You’ll see whether there are any orphan pages present on your site.

To solve this potential problem, add internal links to orphan pages from relevant pages on your site.
5. Bad Sitemap Management
A sitemap provides a list of pages on your site that you want search engines to crawl, index, and rank.
If your sitemap excludes pages intended to be crawled, they might go unnoticed. And create crawlability issues.
Solve by recreating a sitemap that includes all the pages meant to be crawled.
A tool such as XML Sitemaps can help.
Enter your website URL, and the tool will generate a sitemap for you automatically.

Then, save the file as “sitemap.xml” and upload it to the root directory of your website.
For example, if your website is www.example.com, then your sitemap URL should be accessed at www.example.com/sitemap.xml.
Finally, submit your sitemap to Google in your Google Search Console account.
Click “Sitemaps” in the left-hand menu. Enter your sitemap URL and click “Submit.”

6. ‘Noindex’ Tags
A “noindex” meta robots tag instructs search engines not to index the page.
The tag looks like this:
<meta name="robots" content="noindex">
Although the “noindex” tag is intended to control indexing, it can create crawlability issues if you leave it on your pages for a long time.
Google treats long-term “noindex” tags as “nofollow,” as confirmed by Google’s John Muller.
Over time, Google will stop crawling the links on those pages altogether.
So, if your pages are not getting crawled, long-term “noindex” tags could be the culprit.
Identify pages with a “noindex” tag using Semrush’s Site Audit tool.
Set up a project in the tool and run your first crawl.
Once the crawl is complete, head over to the “Issues” tab and search for “noindex.”
The tool will list pages on your site with a “noindex” tag.

Review the pages and remove the “noindex” tag where appropriate.
Note: Having “noindex” tag on some pages—pay-per-click (PPC) landing pages and “thank you” pages, for example—is common practice to keep them out of Google’s index. It’s a problem only when you noindex pages intended to rank in search engines. Remove the “noindex” tag on these pages to avoid indexability and crawlability issues.
7. Slow Site Speed
Site speed is how quickly your site loads. Slow site speed can negatively impact crawlability.
When search engine bots visit your site, they have limited time to crawl—commonly referred to as a crawl budget.
Slow site speed means it takes longer for pages to load. And reduces the number of pages bots can crawl within that crawl session.
Which means important pages could be excluded from crawling.
Work to solve this problem by improving your overall website performance and speed.
Start with our guide to page speed optimization.
8. Internal Broken Links
Broken links are hyperlinks that point to dead pages on your site.
They return a “404 error” like this:

Broken links can have a significant impact on website crawlability.
Search engine bots follow links to discover and crawl more pages on your website.
A broken link acts as a dead end and prevents search engine bots from accessing the linked page.
This interruption can hinder the thorough crawling of your website.
To find broken links on your site, use the Site Audit tool.
Navigate to the “Issues” tab and search for “broken.”
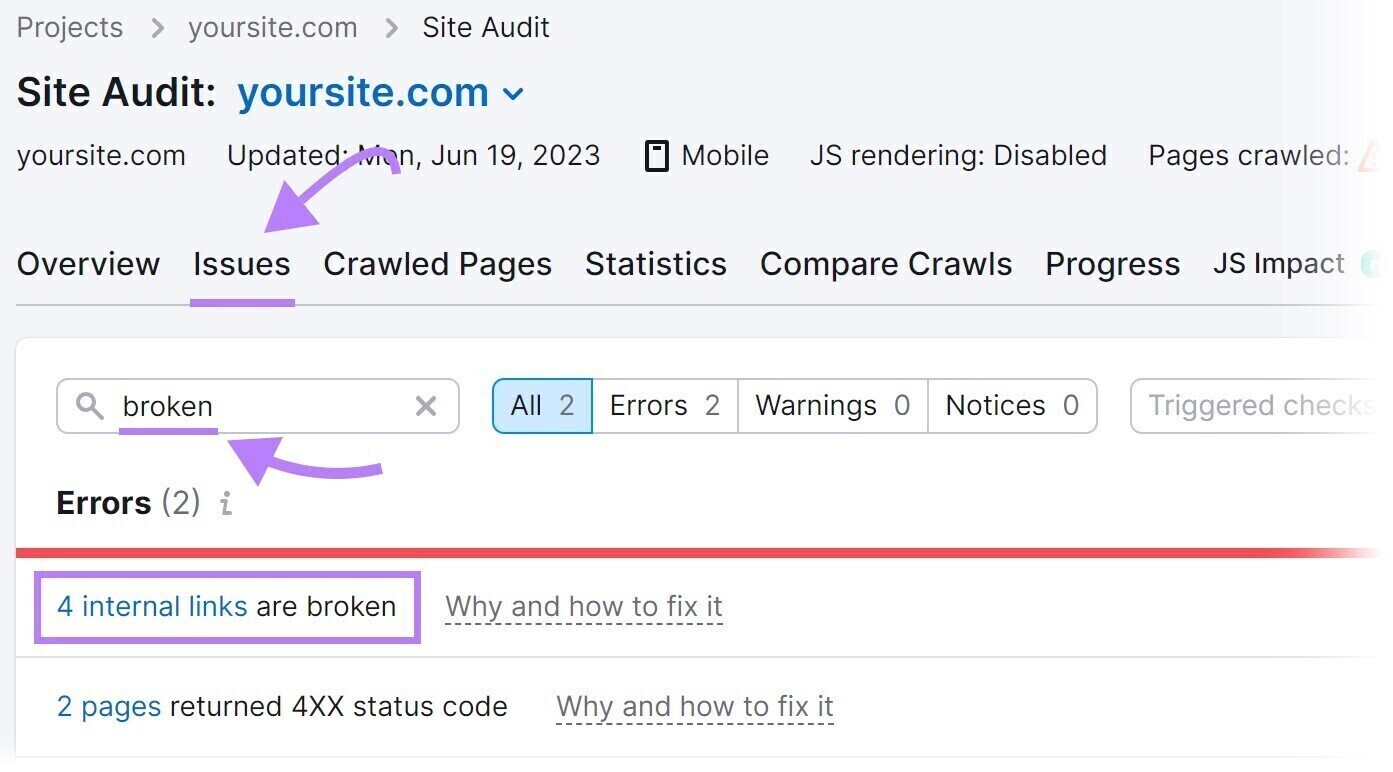
Next, click “# internal links are broken.” You’ll see a report listing all your broken links.

To fix broken links, change the link, restore the missing page, or add a 301 redirect to another relevant page on your site.
9. Server-Side Errors
Server-side errors, such as a 500 HTTP status code, disrupt the crawling process.
Server-side errors indicate that the server couldn’t fulfill the request, which makes it difficult for bots to access and crawl your website’s content.
Regularly monitor your website’s server health to identify and solve for server-side errors.
Semrush’s Site Audit tool can help.
Search for “5xx” in the “Issues” tab to check for server-side errors.

If errors are present, click “# pages returned a 5XX status code” to view a complete list of affected pages.
Then, send this list to your developer to configure the server properly.
10. Redirect Loops
A redirect loop is when one page redirects to another, which in turn redirects back to the original page, forming a continuous loop.

Redirect loops trap search engine bots in an endless cycle of redirects between two (or more) pages.
Bots continue following redirects without reaching the final destination—wasting crucial crawl budget time that could be spent on important pages.
Solve by identifying and fixing redirect loops on your site.
The Site Audit tool can help.
Search for “redirect” in the “Issues” tab.

The tool will display redirect loops and offer advice on how to fix them.

11. Access Restrictions
Pages with access restrictions, such as those behind login forms or paywalls, can prevent search engine bots from crawling and indexing those pages.
As a result, those pages may not appear in search results, limiting their visibility to users.
It makes sense to have certain pages restricted. For example, membership-based websites or subscription platforms often have restricted pages that are accessible only to paying members or registered users.
This allows the site to provide exclusive content, special offers, or personalized experiences. To create a sense of value and incentivize users to subscribe or become members.
But if significant portions of your website are restricted, that’s a crawlability mistake.
Assess the necessity of restricted access for each page. Keep restrictions on pages that truly require them. Remove restrictions on others.
Rid Your Website of Crawlability Issues
Crawlability issues affect your SEO performance.
Semrush’s Site Audit tool is a one-stop solution for detecting and fixing issues that affect crawlability.
Sign up for free to get started.
Source link : Semrush.com