

Wondering why some of your pages don’t show up in Google’s search results?
Crawlability problems could be the culprits.
In this guide, we’ll cover what crawlability problems are, how they affect SEO, and how to fix them.
Let’s get started.
What Are Crawlability Problems?
Crawlability problems are issues that prevent search engines from accessing your website’s pages.
Search engines like Google use automated bots to read and analyze your pages—this is called crawling.

But these bots may encounter obstacles that hinder their ability to properly access your pages if there are crawlability problems.
Common crawlability problems include:
- Nofollow links (which tell Google not to follow the link or pass ranking strength to that page)
- Redirect loops (when two pages redirect to each other to create an infinite loop)
- Bad site structure
- Slow site speed
How Do Crawlability Issues Affect SEO?
Crawlability problems can drastically affect your SEO game.
Why?
Because crawlability problems make it so that some (or all) of your pages are practically invisible to search engines.
They can’t find them. Which means they can’t index them—i.e., save them in a database to display in relevant search results.
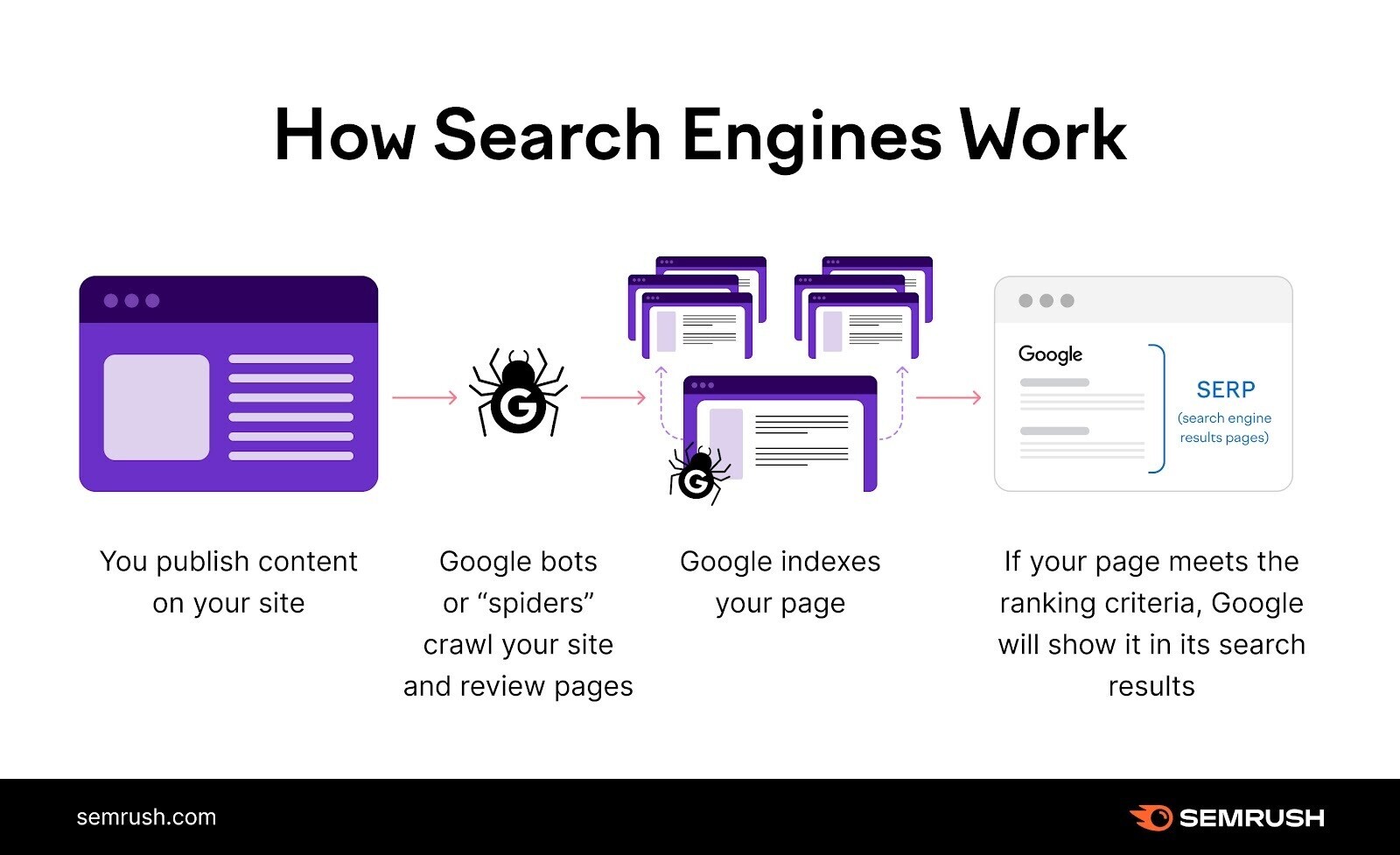
This means a potential loss of search engine (organic) traffic and conversions.
Your pages must be both crawlable and indexable to rank in search engines.
15 Crawlability Problems & How to Fix Them
1. Pages Blocked In Robots.txt
Search engines first look at your robots.txt file. This tells them which pages they should and shouldn’t crawl.
If your robots.txt file looks like this, it means your entire website is blocked from crawling:
User-agent: *
Disallow: /
Fixing this problem is simple. Just replace the “disallow” directive with “allow.” Which should enable search engines to access your entire website.
Like this:
User-agent: *
Allow: /
In other cases, only certain pages or sections are blocked. For instance:
User-agent: *
Disallow: /products/
Here, all the pages in the “products” subfolder are blocked from crawling.
Solve this problem by removing the subfolder or page specified—search engines ignore the empty “disallow” directive.
User-agent: *
Disallow:
Or you could use the “allow” directive instead of “disallow” to instruct search engines to crawl your entire site like we did earlier.
2. Nofollow Links
The nofollow tag tells search engines not to crawl the links on a webpage.
And the tag looks like this:
<meta name="robots" content="nofollow">
If this tag is present on your pages, the other pages that they link to might not get crawled. Which creates crawlability problems on your site.
Check for nofollow links like this with Semrush’s Site Audit tool.
Open the tool, enter your website, and click “Start Audit.”
The “Site Audit Settings” window will appear.
From here, configure the basic settings and click “Start Site Audit.”
Once the audit is complete, navigate to the “Issues” tab and search for “nofollow.”
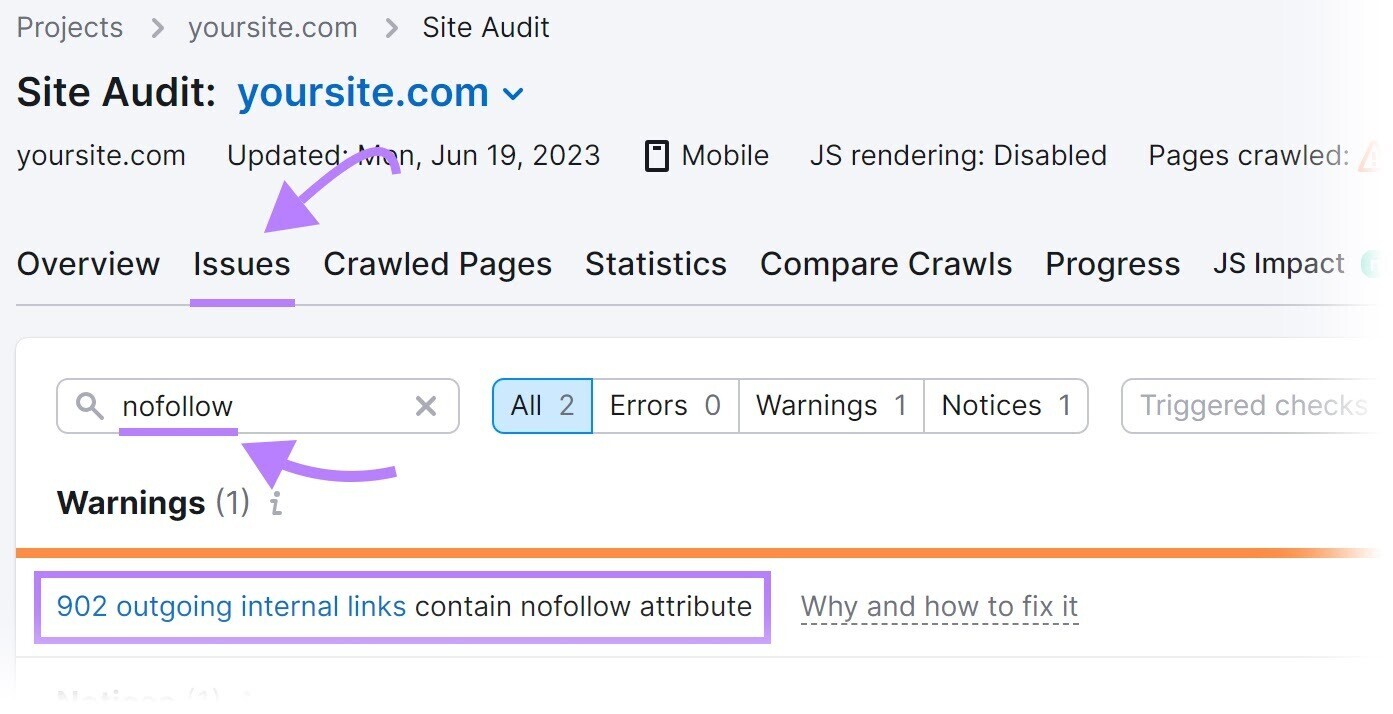
If nofollow links are detected, click “# outgoing internal links contain nofollow attribute” to view a list of pages that have a nofollow tag.
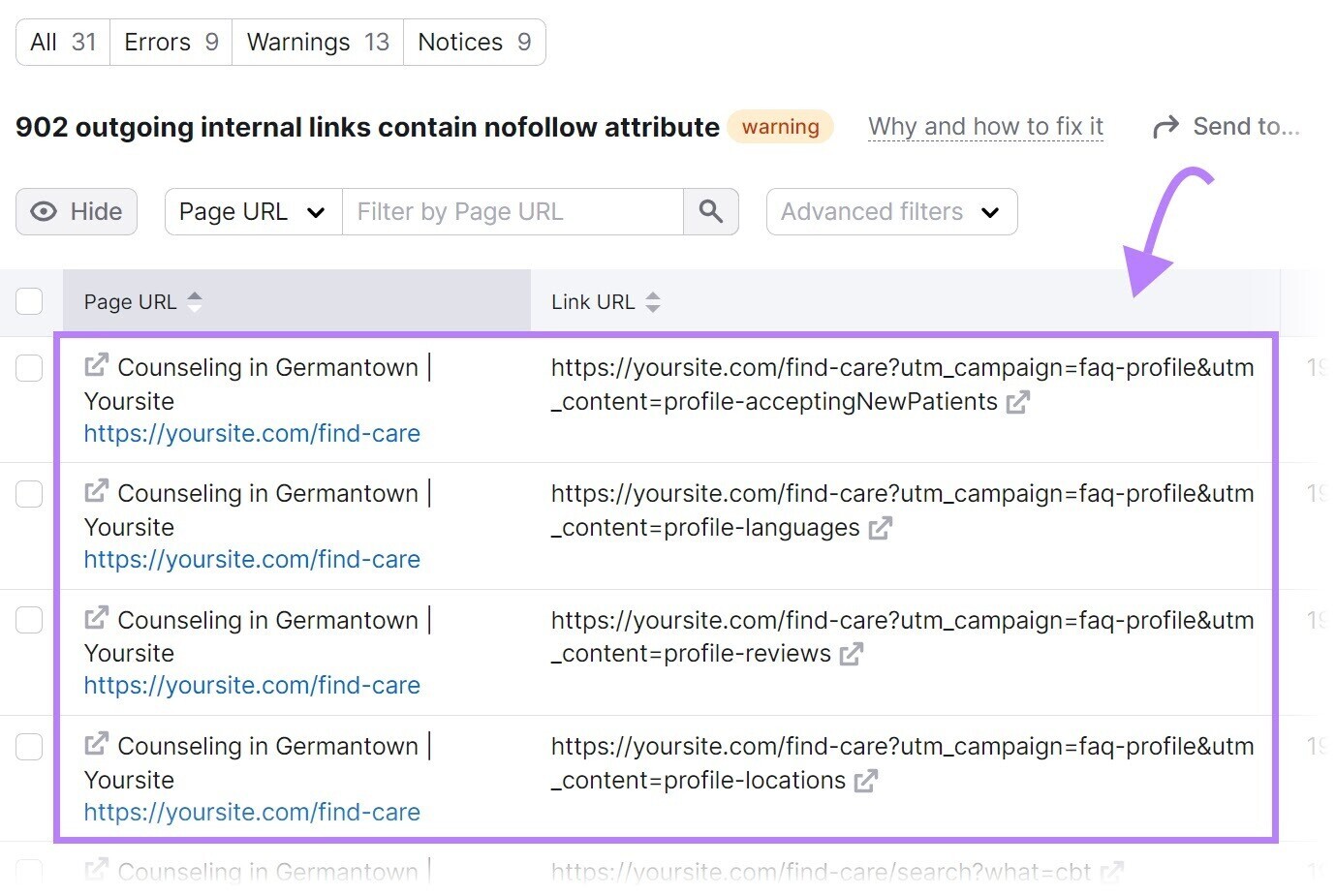
Review the pages and remove the nofollow tags if they shouldn’t be there.
3. Bad Site Architecture
Site architecture is how your pages are organized across your website.
A good site architecture ensures every page is just a few clicks away from the homepage—and that there are no orphan pages (i.e., pages with no internal links pointing to them). To help search engines easily access all pages.
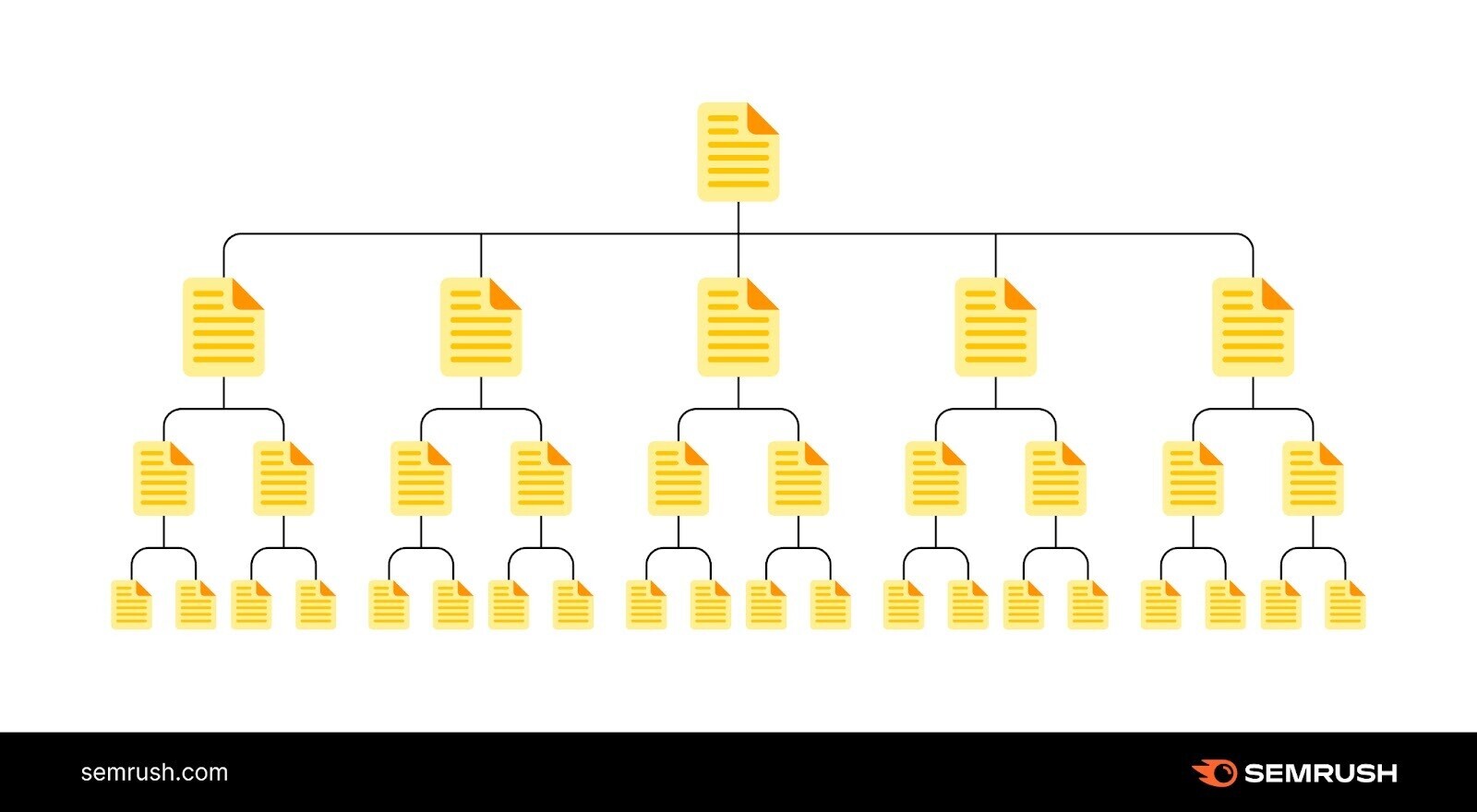
But a bad site site architecture can create crawlability issues.
Notice the example site structure depicted below. It has orphan pages.
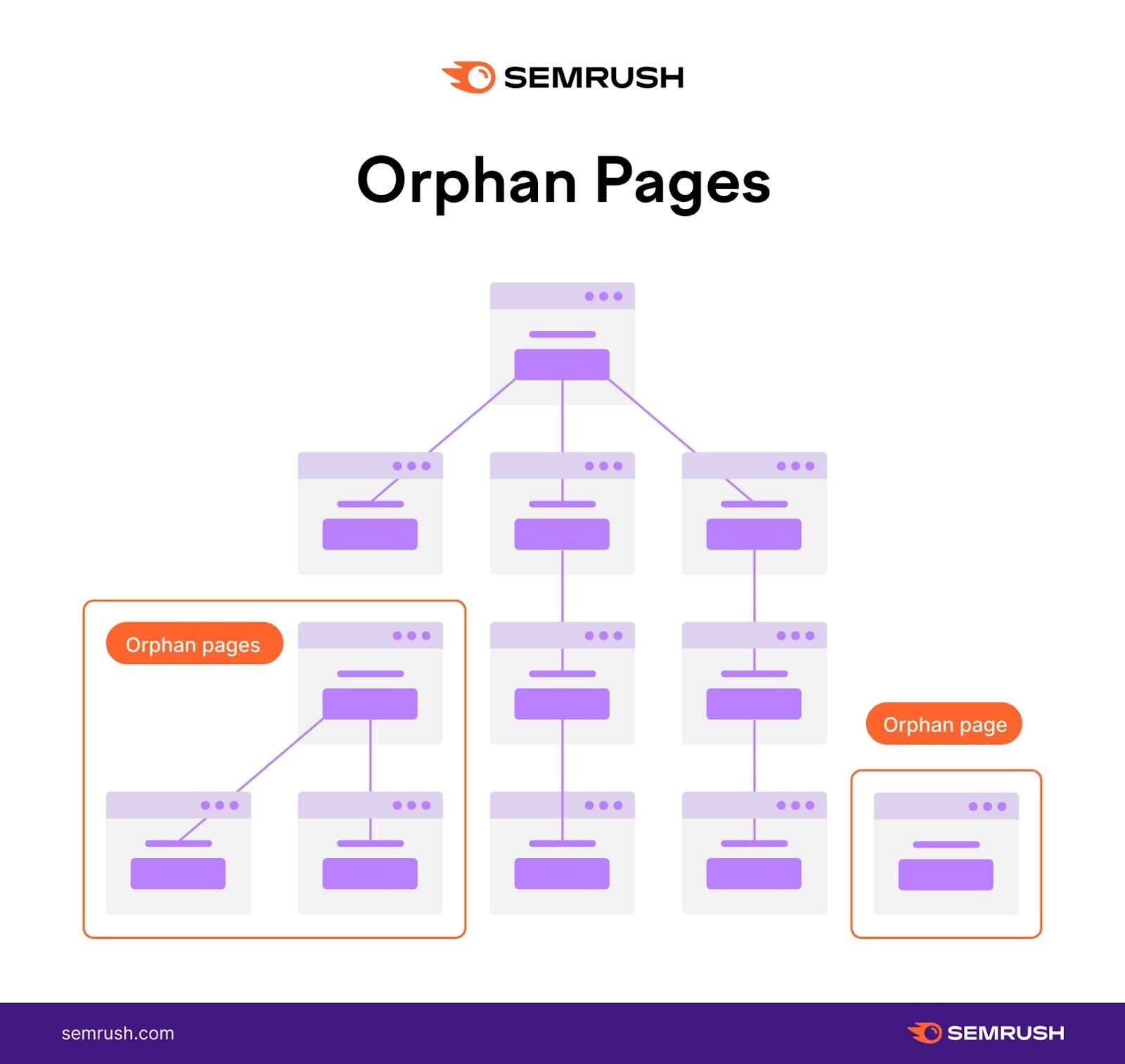
Because there’s no linked path to them from the homepage, they may go unnoticed when search engines crawl the site.
The solution is straightforward: Create a site structure that logically organizes your pages in a hierarchy through internal links.
Like this:
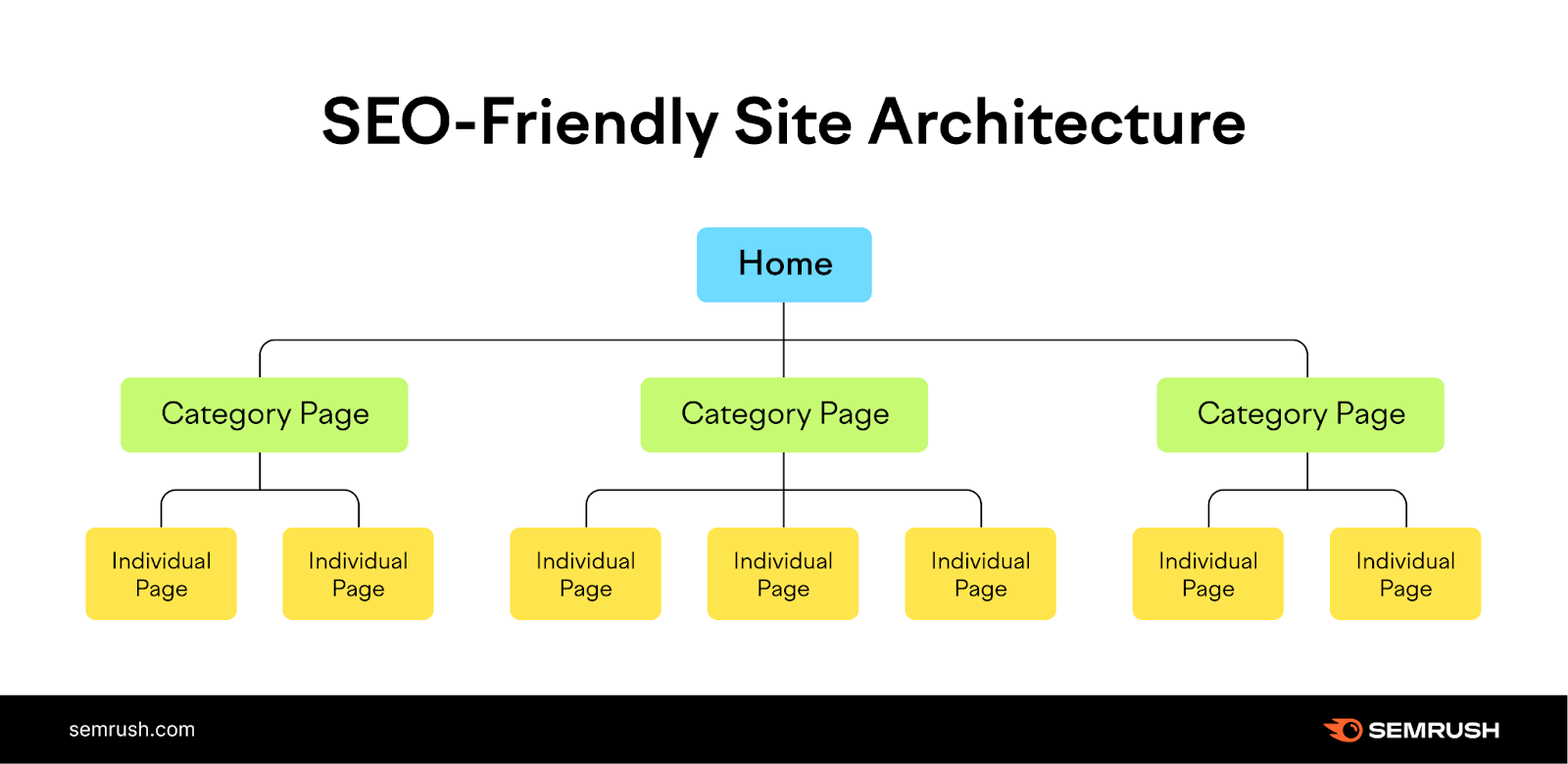
In the example above, the homepage links to category pages, which then link to individual pages on your site.
And this provides a clear path for crawlers to find all your important pages.
4. Lack of Internal Links
Pages without internal links can create crawlability problems.
Search engines will have trouble discovering those pages.
So, identify your orphan pages. And add internal links to them to avoid crawlability issues.
Find orphan pages using Semrush’s Site Audit tool.
Configure the tool to run your first audit.
Then, go to the “Issues” tab and search for “orphan.”
You’ll see whether there are any orphan pages present on your site.
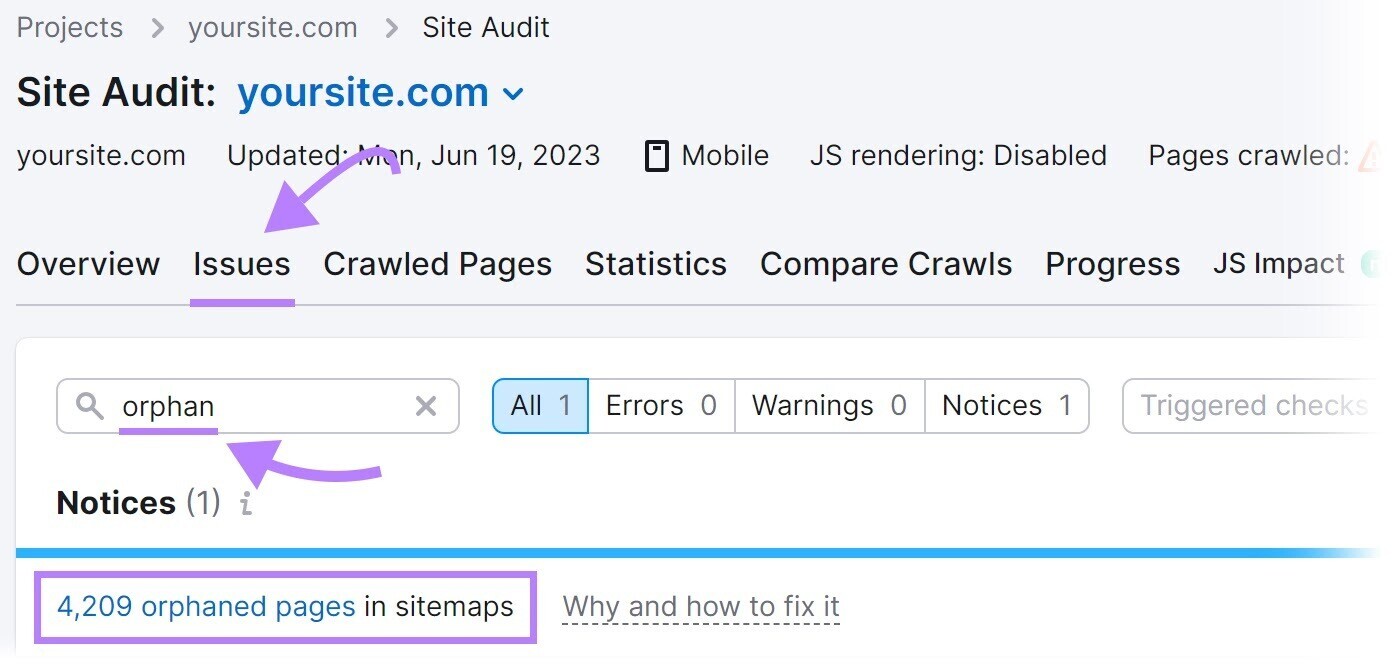
To solve this problem, add internal links to orphan pages from other relevant pages on your site.
5. Bad Sitemap Management
A sitemap provides a list of pages on your site that you want search engines to crawl, index, and rank.
If your sitemap excludes any pages you want to be found, they might go unnoticed. And create crawlability issues. A tool such as XML Sitemaps Generator can help you include all pages meant to be crawled.
Enter your website URL, and the tool will generate a sitemap for you automatically.
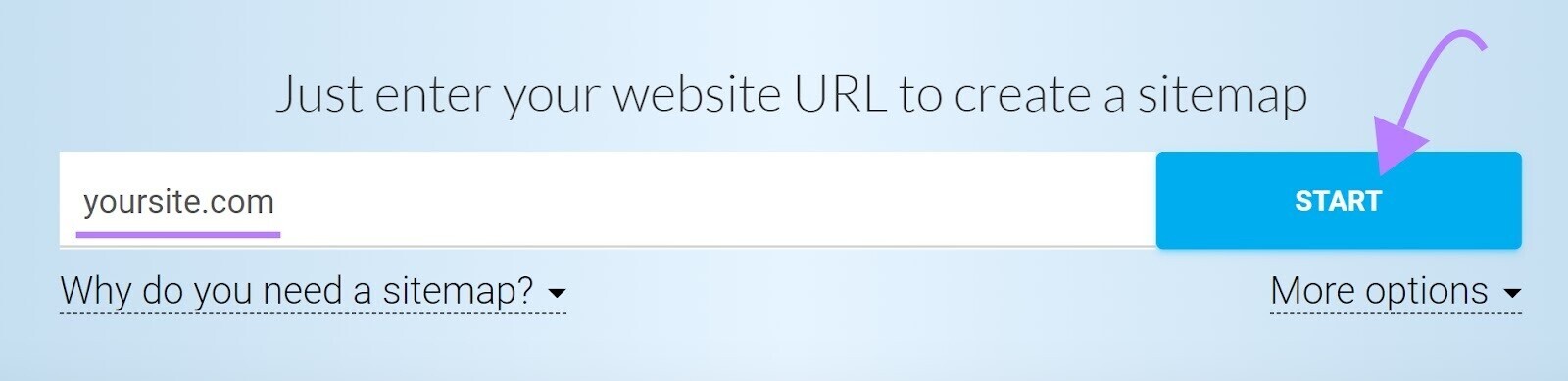
Then, save the file as “sitemap.xml” and upload it to the root directory of your website.
For example, if your website is www.example.com, then your sitemap URL should be accessed at www.example.com/sitemap.xml.
Finally, submit your sitemap to Google in your Google Search Console account.
To do that, access your account.
Click “Sitemaps” in the left-hand menu. Then, enter your sitemap URL and click “Submit.”

6. ‘Noindex’ Tags
A “noindex” meta robots tag instructs search engines not to index a page.
And the tag looks like this:
<meta name="robots" content="noindex">
Although the noindex tag is intended to control indexing, it can create crawlability issues if you leave it on your pages for a long time.
Google treats long-term “noindex” tags as nofollow tags, as confirmed by Google’s John Mueller.
Over time, Google will stop crawling the links on those pages altogether.
So, if your pages aren’t getting crawled, long-term noindex tags could be the culprit.
Identify these pages using Semrush’s Site Audit tool.
Set up a project in the tool to run your first crawl.
Once it’s complete, head over to the “Issues” tab and search for “noindex.”
The tool will list pages on your site with a “noindex” tag.
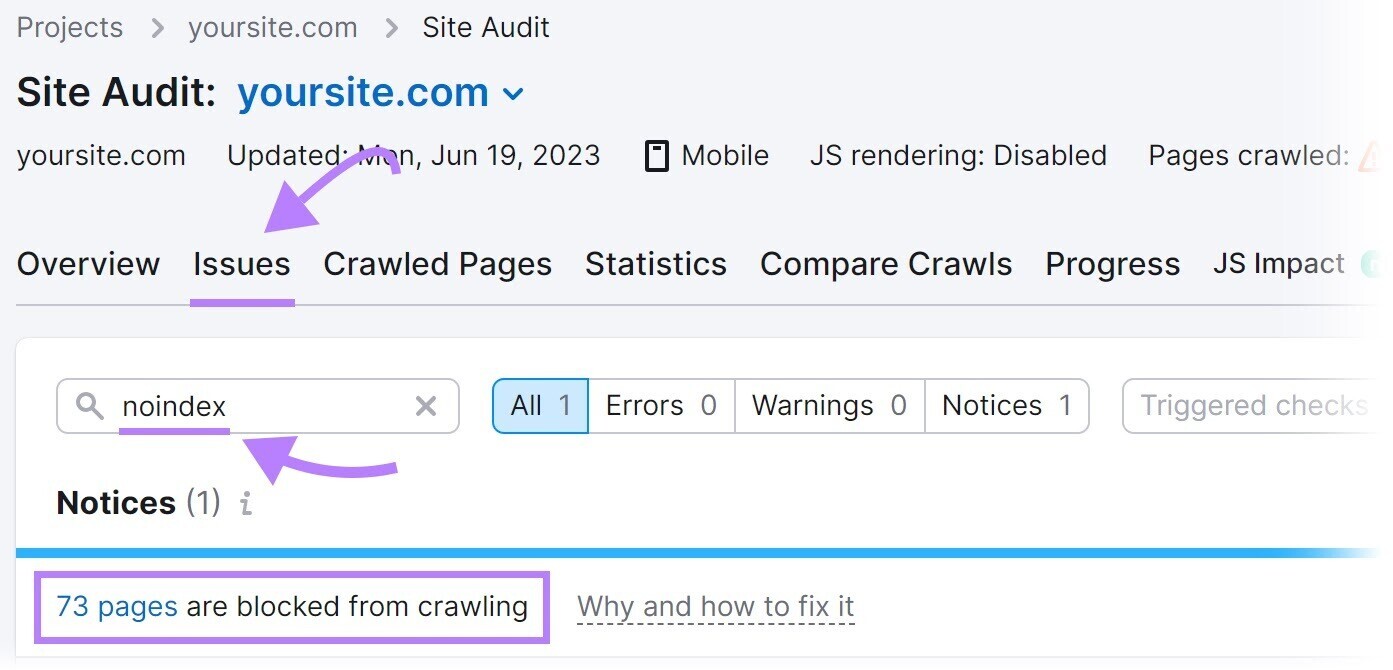
Review these pages and remove the “noindex” tag where appropriate.
7. Slow Site Speed
When search engine bots visit your site, they have limited time and resources to devote to crawling—commonly referred to as a crawl budget.
Slow site speed means it takes longer for pages to load. And reduces the number of pages bots can crawl within that crawl session.
Which means important pages could be excluded.
Work to solve this problem by improving your overall website performance and speed.
Start with our guide to page speed optimization.
8. Internal Broken Links
Internal broken links are hyperlinks that point to dead pages on your site.
They return a 404 error like this:
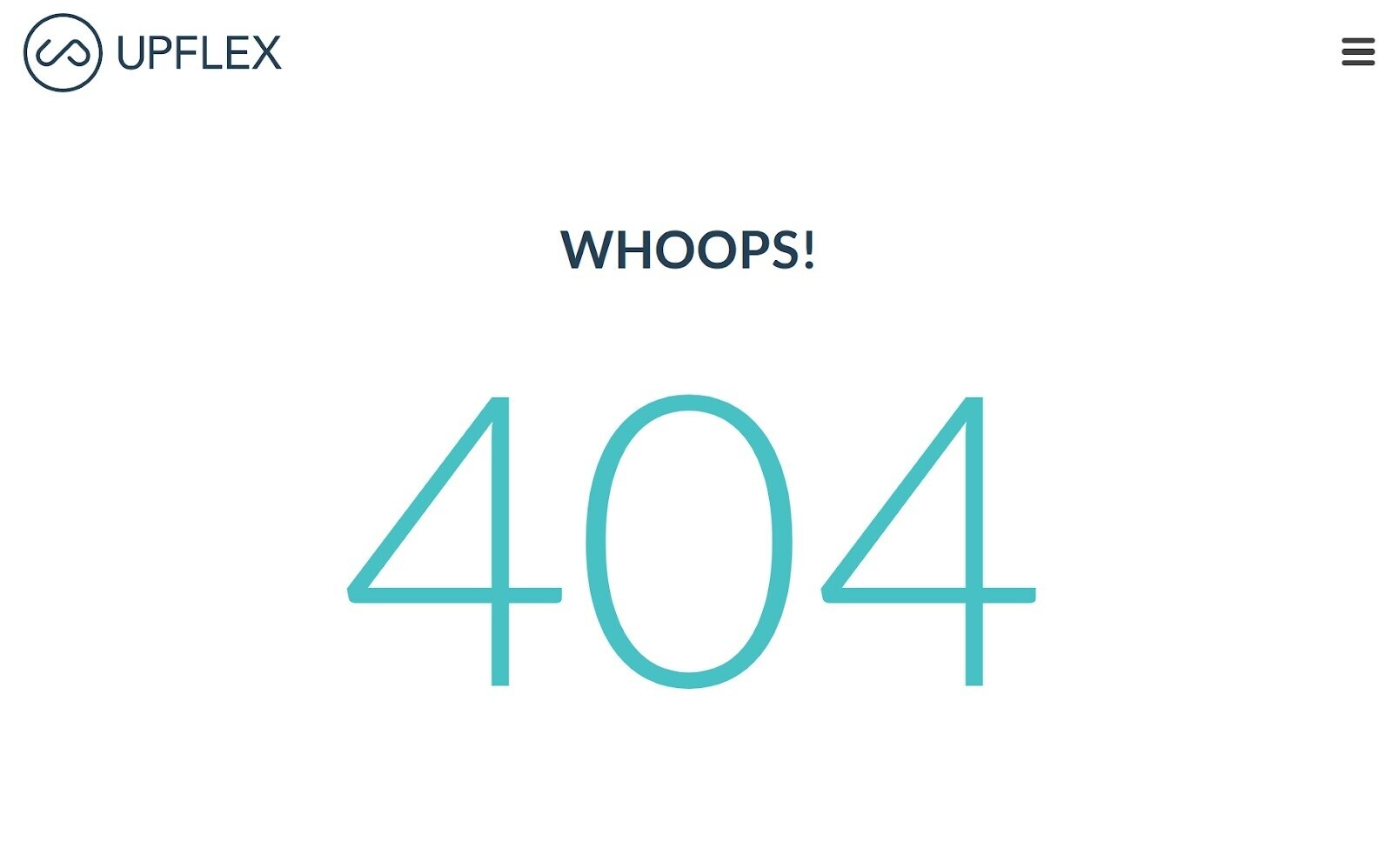
Broken links can have a significant impact on website crawlability. Because they prevent search engine bots from accessing the linked pages.
To find broken links on your site, use the Site Audit tool.
Navigate to the “Issues” tab and search for “broken.”
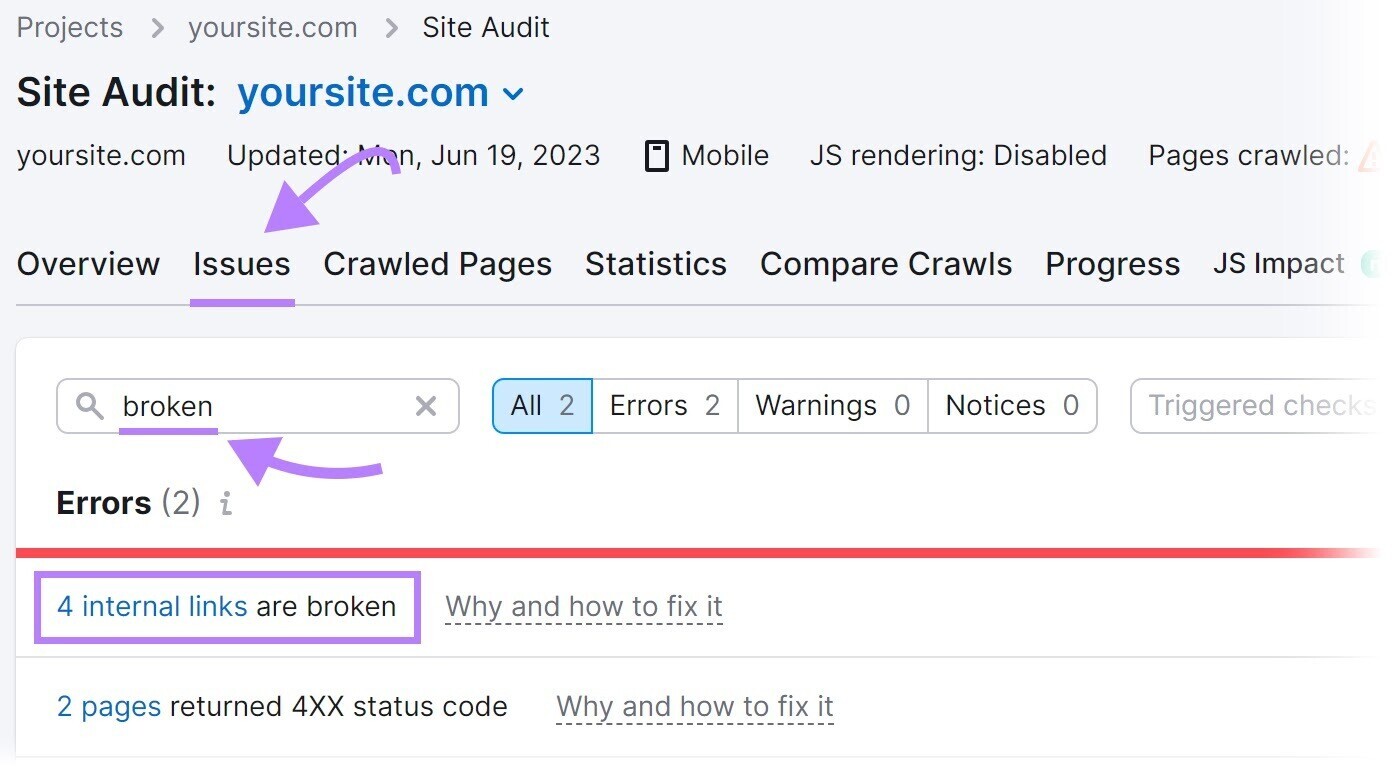
Next, click “# internal links are broken.” And you’ll see a report listing all your broken links.
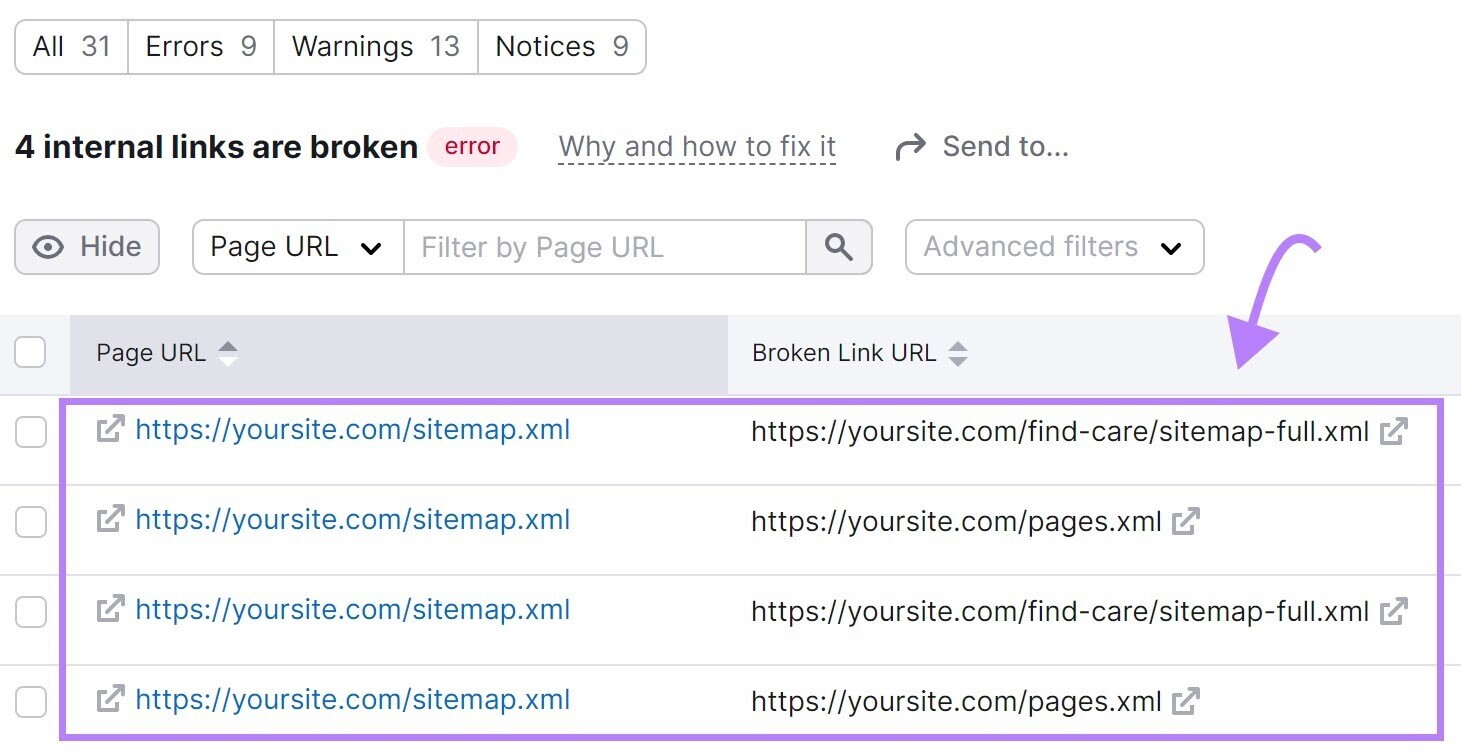
To fix these broken links, substitute a different link, restore the missing page, or add a 301 redirect to another relevant page on your site.
9. Server-Side Errors
Server-side errors (like 500 HTTP status codes) disrupt the crawling process because they mean the server couldn’t fulfill the request. Which makes it difficult for bots to crawl your website’s content.
Semrush’s Site Audit tool can help you solve for server-side errors.
Search for “5xx” in the “Issues” tab.
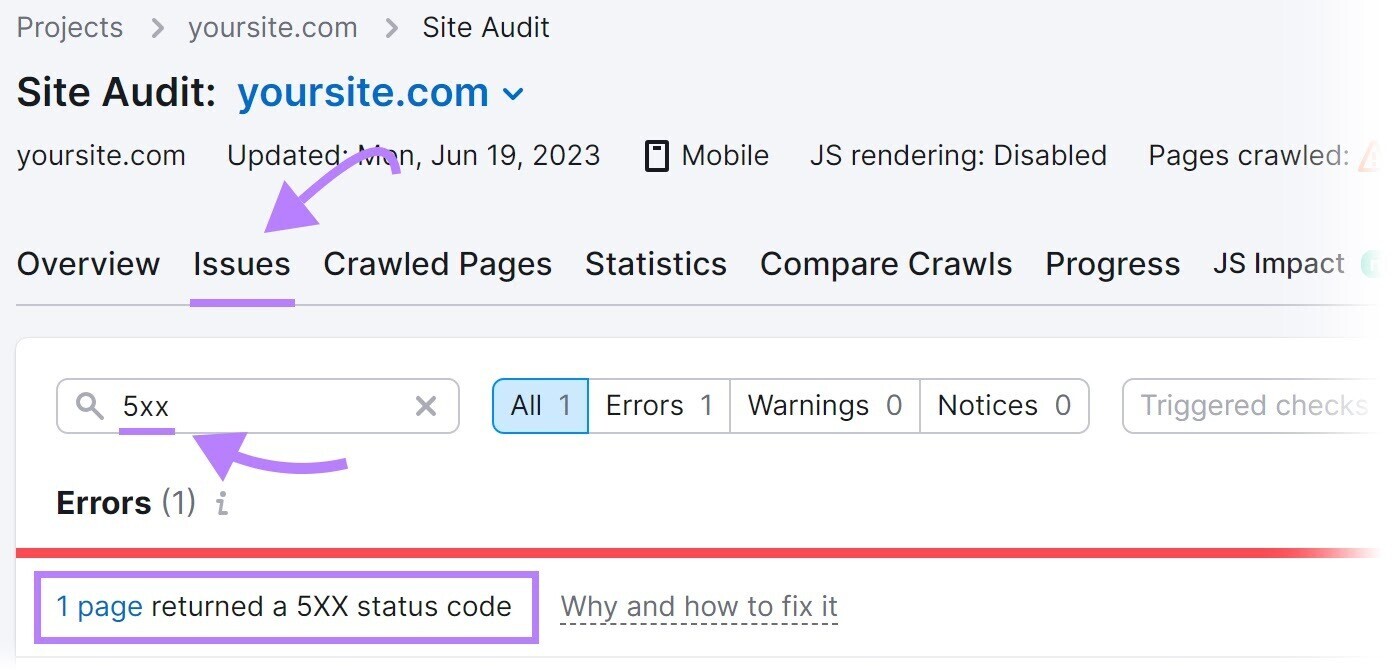
If errors are present, click “# pages returned a 5XX status code” to view a complete list of affected pages.
Then, send this list to your developer to configure the server properly.
10. Redirect Loops
A redirect loop is when one page redirects to another, which then redirects back to the original page. And forms a continuous loop.
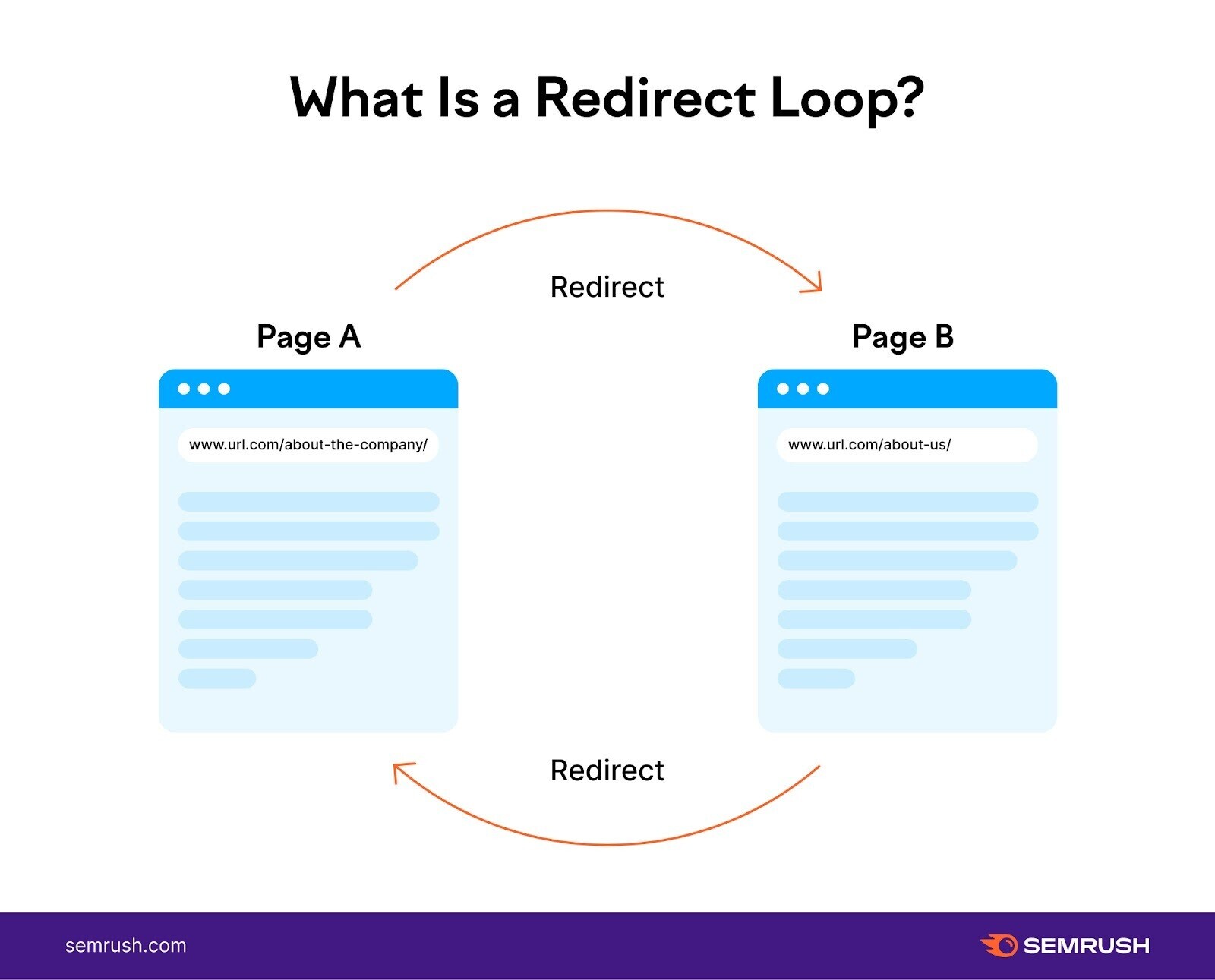
Redirect loops prevent search engine bots from reaching a final destination by trapping them in an endless cycle of redirects between two (or more) pages. Which wastes crucial crawl budget time that could be spent on important pages.
Solve this by identifying and fixing redirect loops on your site with the Site Audit tool.
Search for “redirect” in the “Issues” tab.
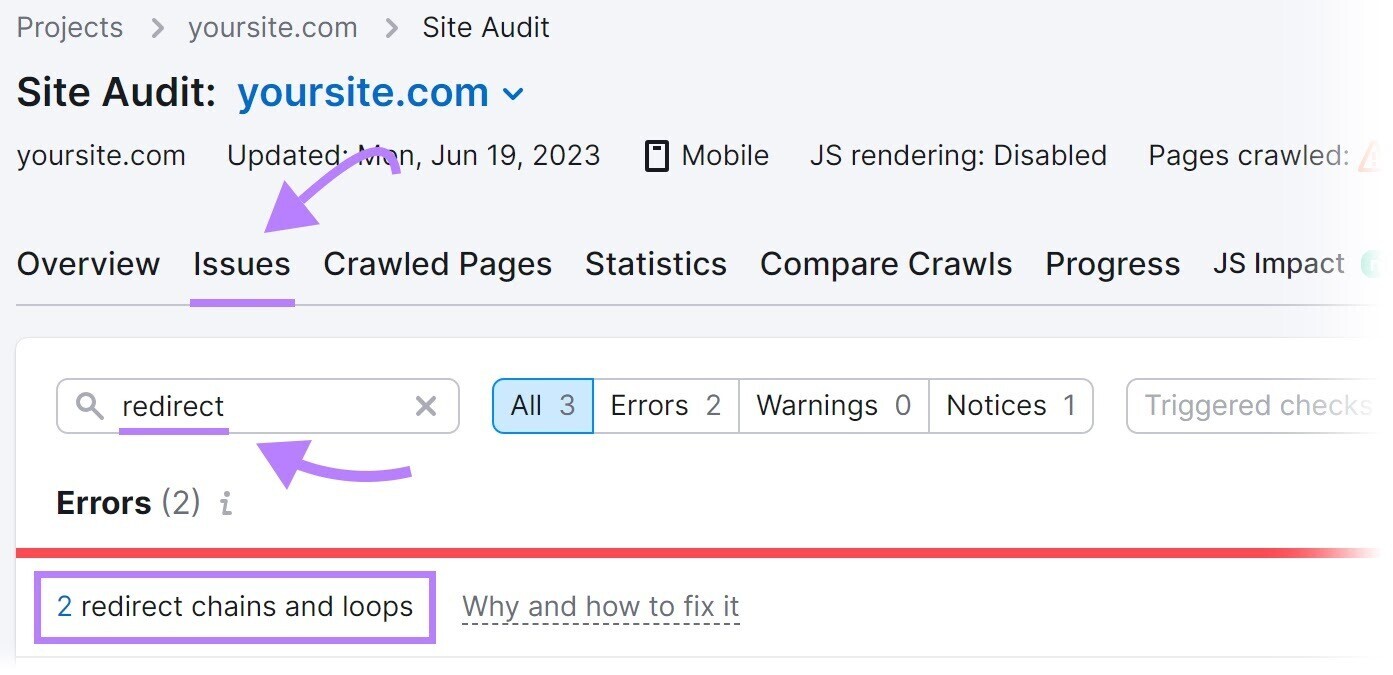
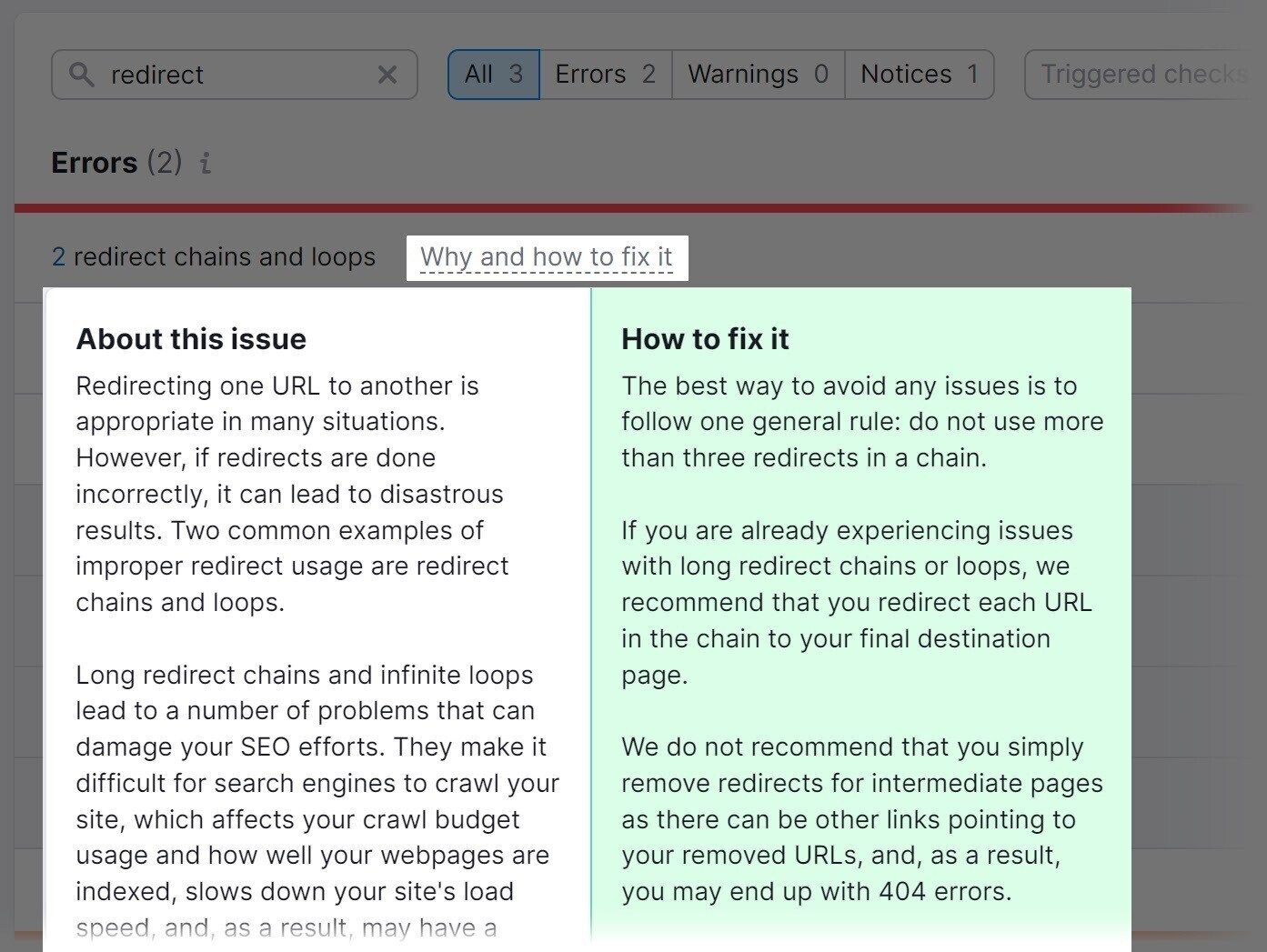
The tool will display redirect loops. And offer advice on how to address them when you click “Why and how to fix it.”
11. Access Restrictions
Pages with access restrictions (like those behind login forms or paywalls) can prevent search engine bots from crawling them.
As a result, those pages may not appear in search results, limiting their visibility to users.
It makes sense to have certain pages restricted.
For example, membership-based websites or subscription platforms often have restricted pages that are accessible only to paying members or registered users.
This allows the site to provide exclusive content, special offers, or personalized experiences. To create a sense of value and incentivize users to subscribe or become members.
But if significant portions of your website are restricted, that’s a crawlability mistake.
So, assess the need for restricted access for each page and keep them on pages that truly require them. Remove restrictions on those that don’t.
12. URL Parameters
URL parameters (also known as query strings) are parts of a URL that help with tracking and organization and follow a question mark (?). Like example.com/shoes?color=blue
And they can significantly impact your website’s crawlability.
How?
URL parameters can create an almost infinite number of URL variations.
You’ve probably seen that on ecommerce category pages. When you apply filters (size, color, brand, etc.), the URL often changes to reflect these selections.
And if your website has a large catalog, suddenly you have thousands or even millions of URLs across your site.
If they aren’t managed well, Google will waste the crawl budget on the parameterized URLs. Which may result in some of your other important pages not being crawled.
So, you need to decide which URL parameters are helpful for search and should be crawled. Which you can do by understanding whether people are searching for the specific content the page generates when a parameter is applied.
For example, people often like to search by the color they’re looking for when shopping online.
For example, “black shoes.”
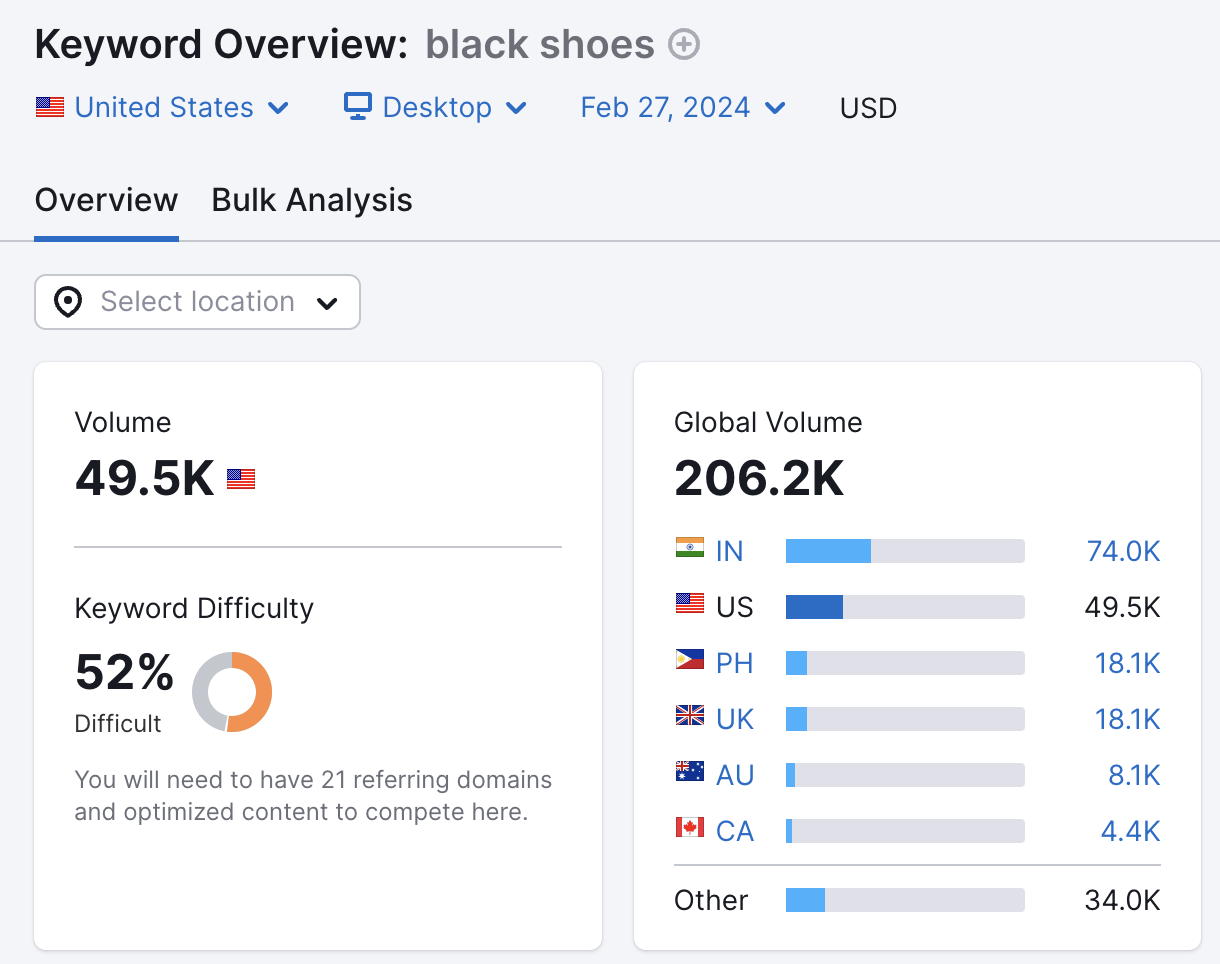
This means the “color” parameter is helpful. And a URL like example.com/shoes?color=black should be crawled.
But some parameters aren’t helpful for search and shouldn’t be crawled.
For example, the “rating” parameter that filters the products by their customer ratings. Such as example.com/shoes?rating=5.
Almost nobody searches for shoes by the customer rating.
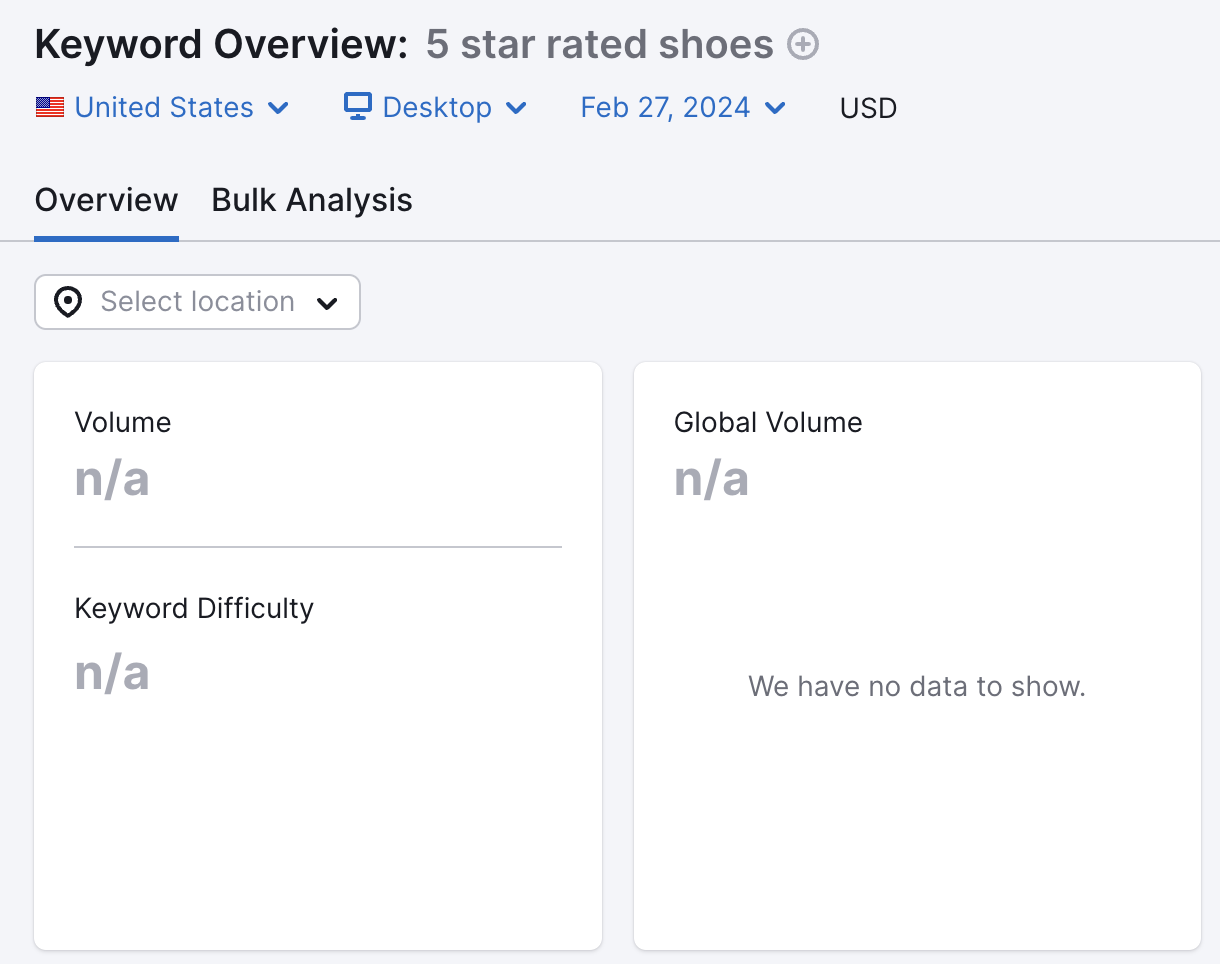
That means you should prevent URLs that aren’t helpful for search from being crawled. Either by using a robots.txt file or using the nofollow tag for internal links to those parameterized URLs.
Doing so will ensure your crawl budget is being spent efficiently. And on the right pages.
13. JavaScript Resources Blocked in Robots.txt
Many modern websites are built using JavaScript (a popular programming language). And that code is contained in .js files.
But blocking access to these .js files via robots.txt can inadvertently create crawlability issues. Especially if you block essential JavaScript files.
For example, if you block a JavaScript file that loads the main content of a page, the crawlers may not be able to see that content.
So, review your robots.txt file to ensure that you’re not blocking anything important.
Or use Semrush’s Site Audit tool.
Go to the “Issues” tab and search for “blocked.”
If issues are detected, click on the blue links.
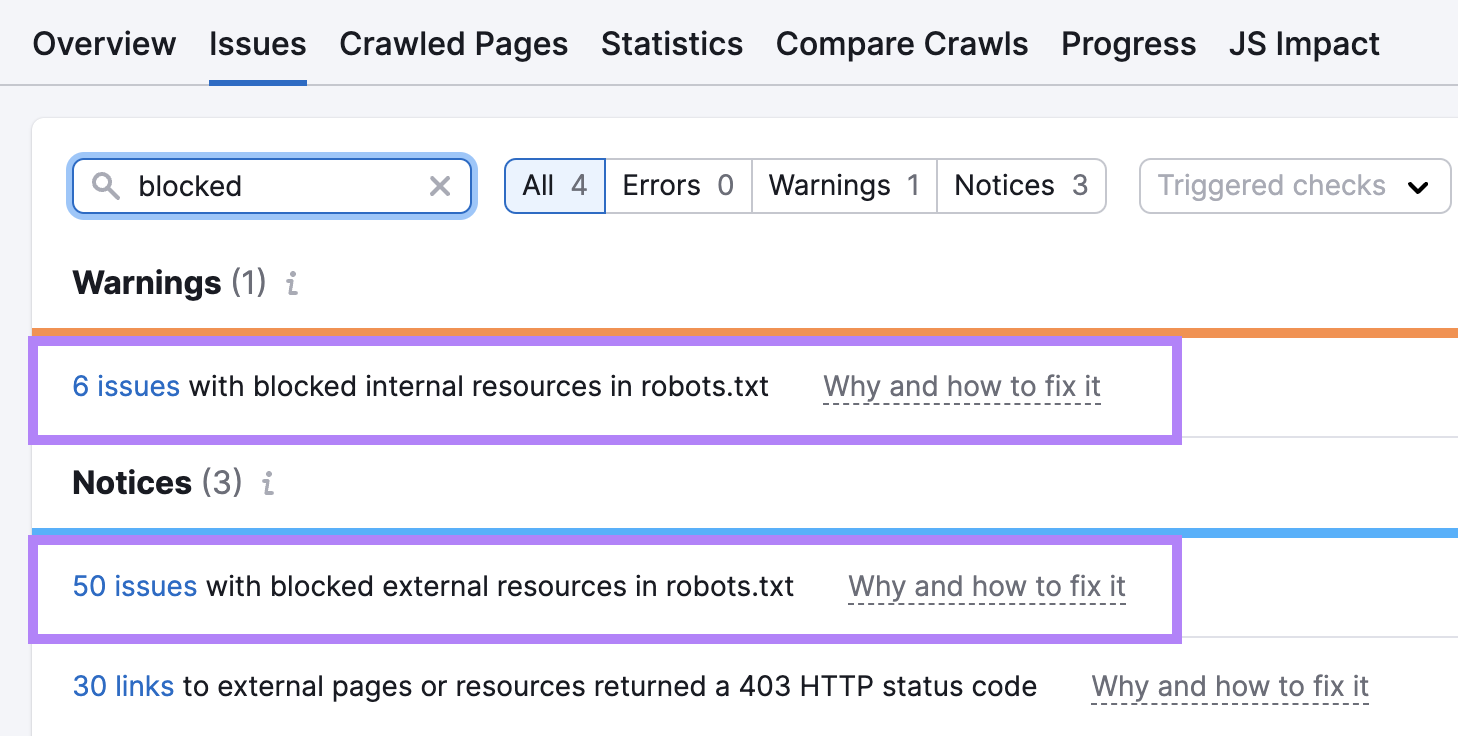
And you’ll see the exact resources that are blocked.
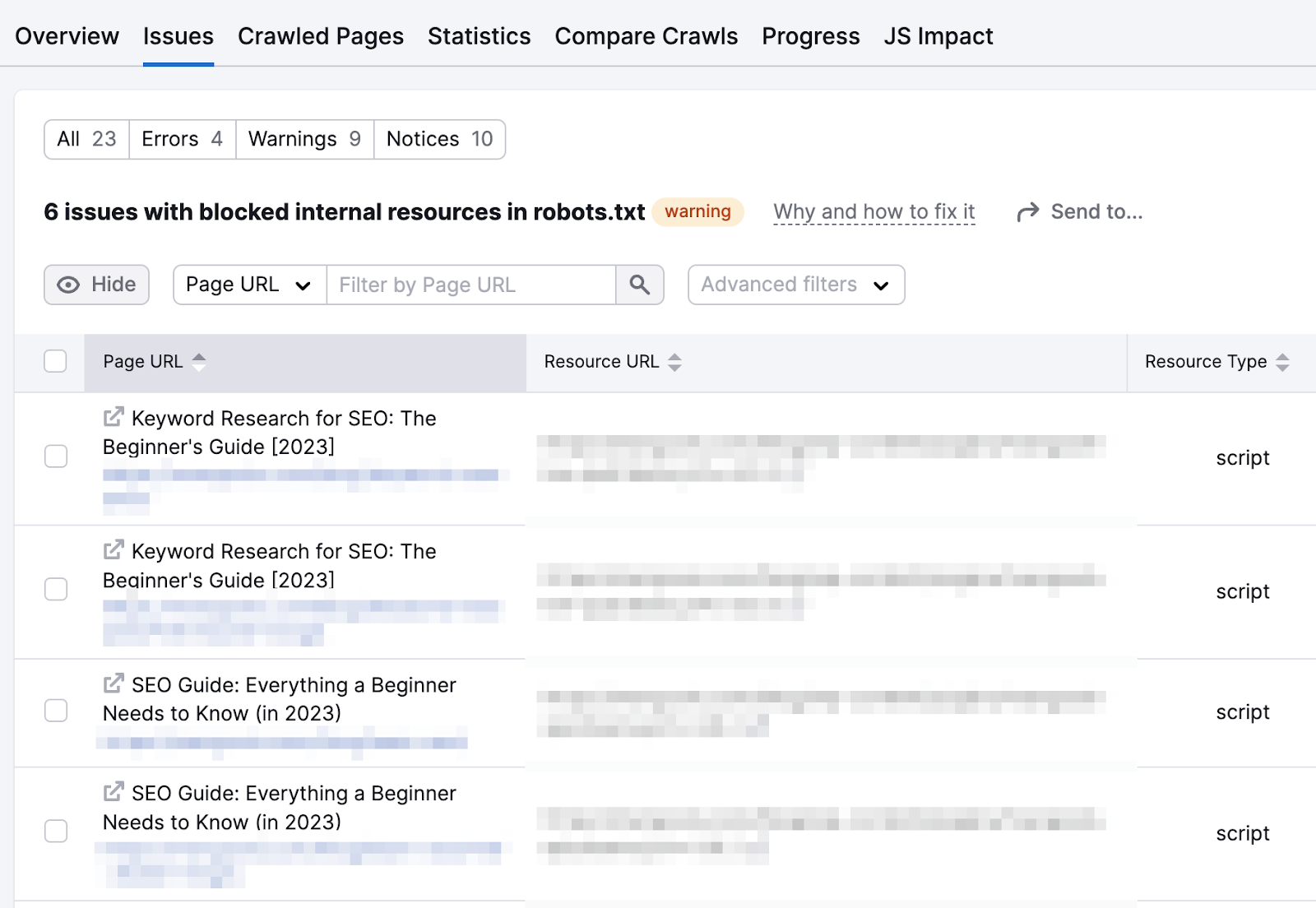
At this point, it’s best to get help from your developer.
They can tell you which JavaScript files are critical for your website’s functionality and content visibility. And shouldn’t be blocked.
14. Duplicate Content
Duplicate content refers to identical or nearly identical content that appears on multiple pages across your website.
For example, imagine you publish a blog post on your site. And that post is accessible via multiple URLs:
- example.com/blog/your-post
- example.com/news/your-post
- example/articles/your-post
Even though the content is the same, the URLs are different. And search engines will aim to crawl all of them.
This wastes crawl budget that could be better spent on other important pages on your website. Use Semrush’s Site Audit to identify and eliminate these problems.
Go to the “Issues” tab and search for “duplicate content.” And you’ll see whether there are any errors detected.
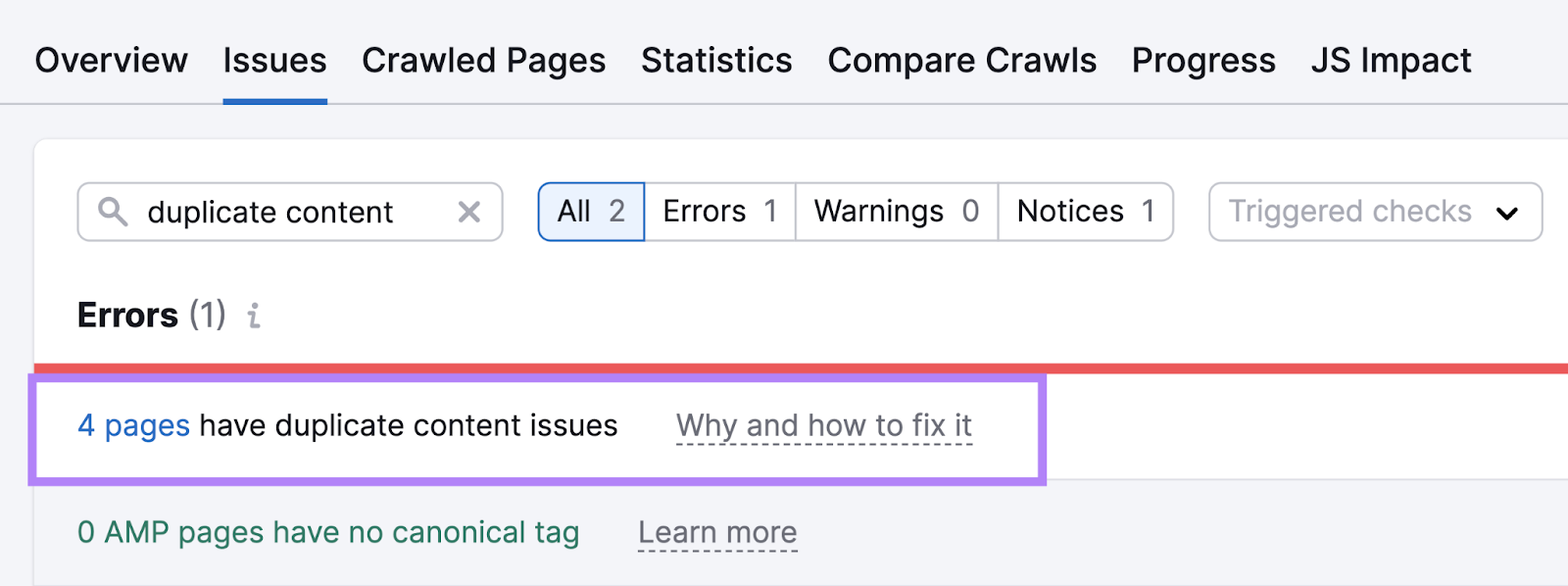
Click the “# pages have duplicate content issues” link to see a list of all the affected pages.
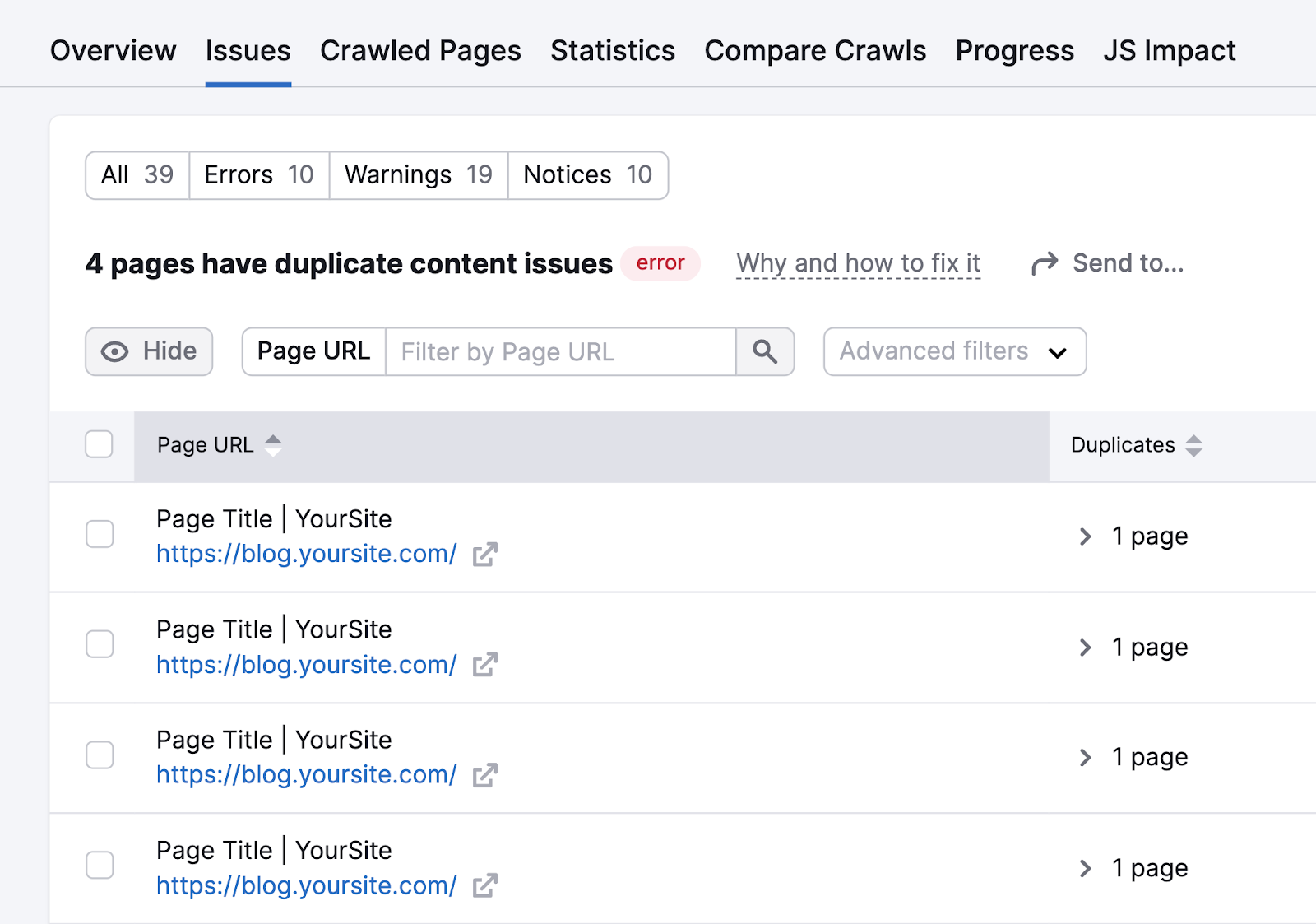
If the duplicates are mistakes, redirect those pages to the main URL that you want to keep.
If the duplicates are necessary (like if you’ve intentionally placed the same content in multiple sections to address different audiences), you can implement canonical tags. Which help search engines identify the main page you want to be indexed.
15. Poor Mobile Experience
Google uses mobile-first indexing. This means they look at the mobile version of your site over the desktop version when crawling and indexing your site.
If your site takes a long time to load on mobile devices, it can affect your crawlability. And Google may need to allocate more time and resources to crawl your entire site.
Plus, if your site isn’t responsive—meaning it doesn’t adapt to different screen sizes or work as intended on mobile devices—Google may find it harder to understand your content and access other pages.
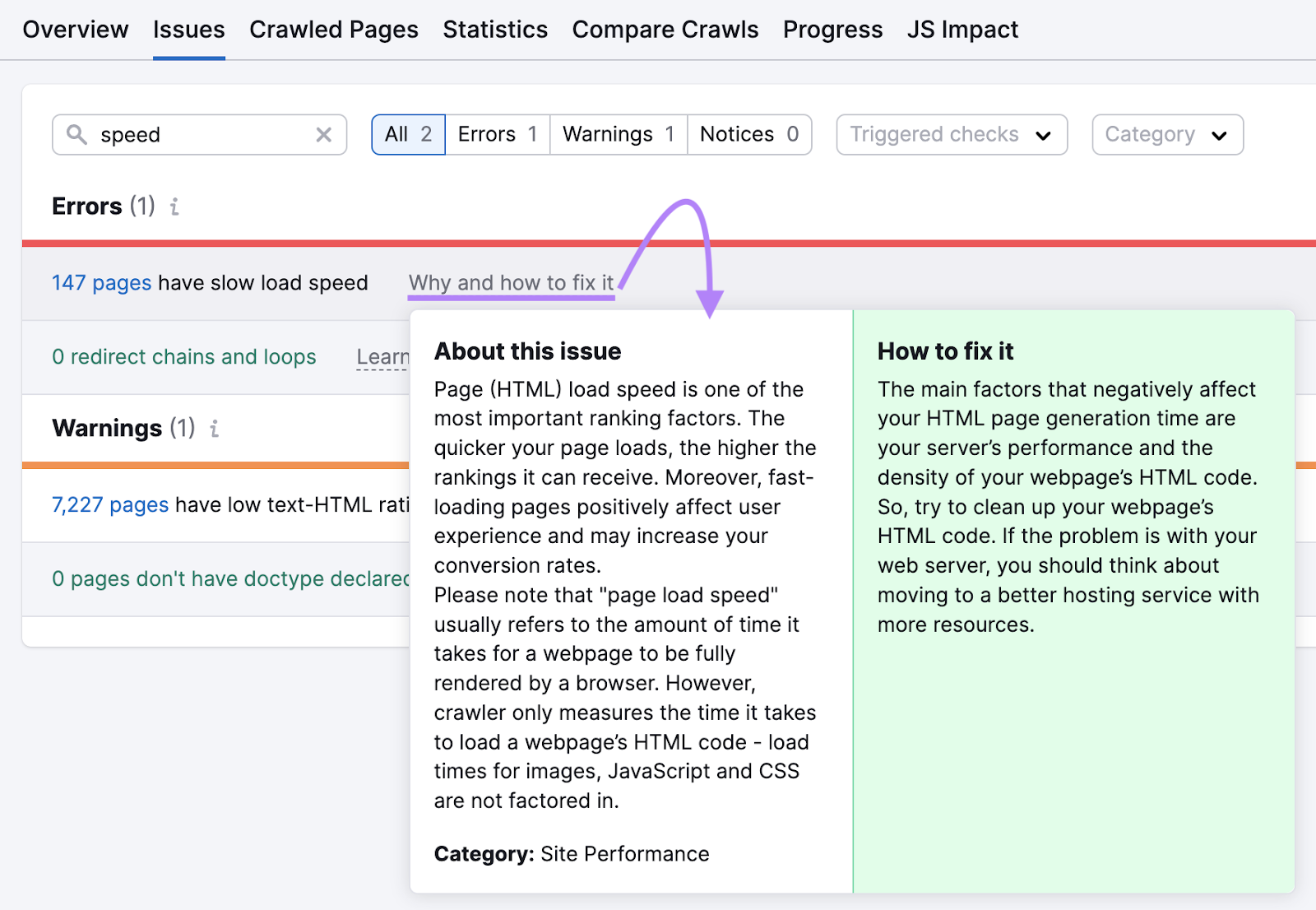
So, review your site to see how it works on mobile. And find slow-loading pages on your site with Semrush’s Site Audit tool.
Navigate to the “Issues” tab and search for “speed.”
The tool will show the error if you have affected pages. And offer advice on how to improve their speed.
Stay Ahead of Crawlability Issues
Crawlability problems aren’t a one-time thing. Even if you solve them now, they might recur in the future. Especially if you have a large website that undergoes frequent changes.
That’s why regularly monitoring your site’s crawlability is so important.
With our Site Audit tool, you can perform automated checks on your site’s crawlability.
Just navigate to the audit settings for your site and turn on weekly audits.
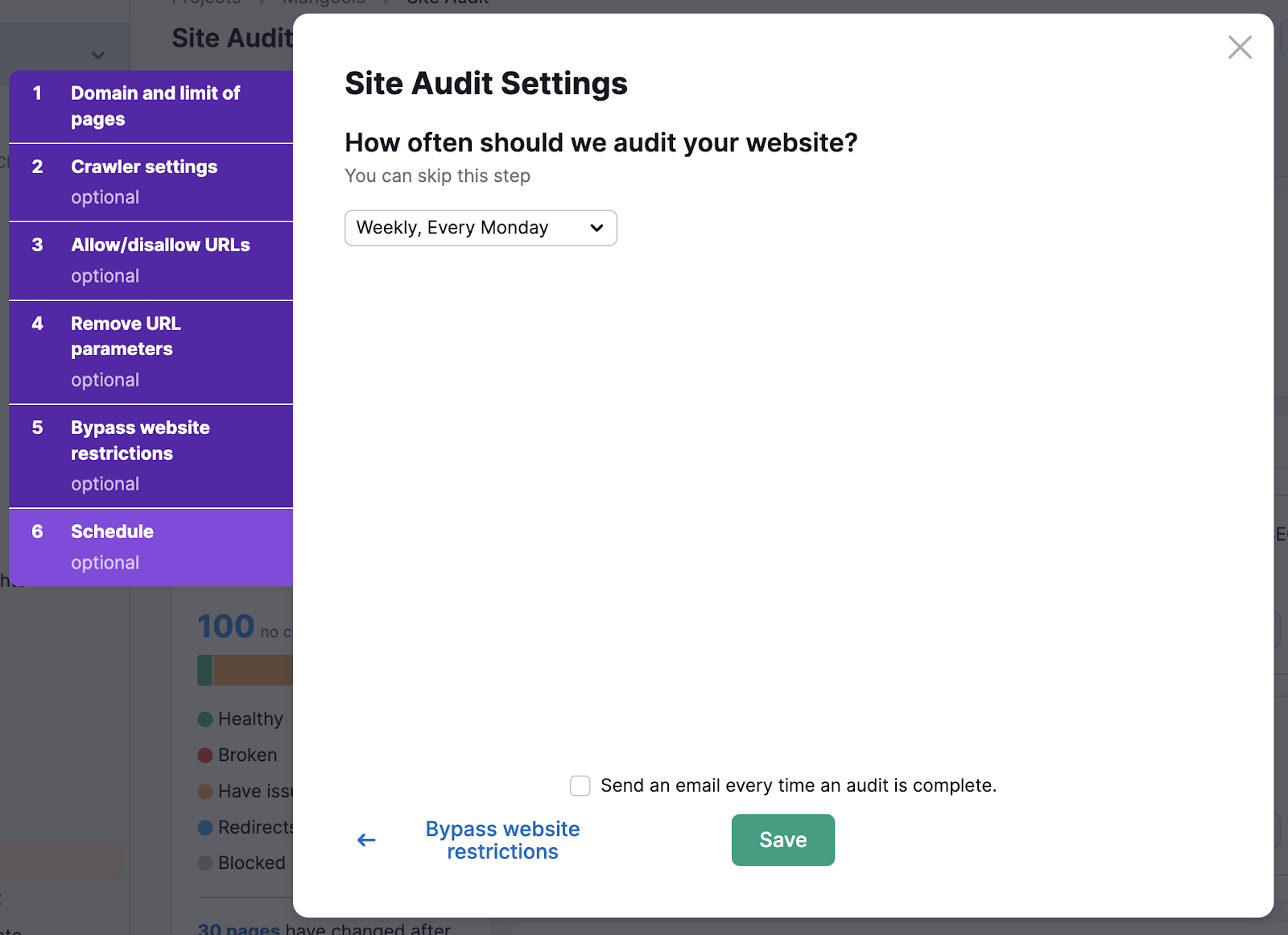
Now, you don’t have to worry about missing any crawability issues.
Source link : Semrush.com