

Introduction
LangChain represents an open-source framework that aims to streamline the development of applications leveraging large language ****** (LLMs). Its primary objective is to establish a standardized interface for chains, boasting numerous integrations with various tools, and offering end-to-end chains for frequently encountered applications. This platform facilitates AI developers in constructing applications that amalgamate Large Language ******, such as GPT-4, with external data sources and computational capabilities. The framework is equipped with both Python and JavaScript packages.

How does langChain work?
LangChain operates based on a fundamental pipeline: the user initiates a query to the language model, which then employs the vector representation of the question to conduct a similarity search within the vector database. Consequently, relevant information is retrieved from the vector database, and the response is subsequently fed back into the language model. This process ultimately culminates in the generation of an answer or the execution of an action by the language model.

Features and Modules:
LangChain encompasses various modules that facilitate the smooth operation of multiple components crucial for effective NLP applications:
- Model Interaction: Also known as model I/O, this module enables seamless interaction with diverse language ******, managing inputs, and extracting relevant information from their outputs.
- Data Integration and Retrieval: This module allows for the transformation, storage, and retrieval of data accessed by LLMs. It facilitates data management through databases and efficient query handling.
- Chains: In building sophisticated applications, this module enables the linkage of multiple LLMs with other components, establishing LLM chains for enhanced functionality and complex operations.
- Agents: Operating as decision-making facilitators, the agent module coordinates intricate commands for LLMs and auxiliary tools, guiding them to execute specific tasks and respond to user requests effectively.
- Memory: This module ensures that LLMs retain context during interactions with users by incorporating both short-term and long-term memory, thereby enhancing their understanding and responsiveness.
- Applications: LangChain boasts a versatile array of applications, leveraging the power of LLMs to create diverse and impactful functionalities. It offers a user-friendly interface and benefits from a thriving community of users and contributors.
Here are some of the key applications of LangChain:
- Document Analysis and Summarization
- Chatbots: Employing LangChain to develop interactive and natural language-based chatbots for customer support, appointment scheduling, and client inquiries.
- Code Analysis: Utilizing LangChain for comprehensive code analysis, identifying potential bugs and security vulnerabilities.
- Source-Driven Question Answering: Leveraging LangChain’s capabilities to answer queries by sourcing information from various repositories such as text, code, and data.
- Data Augmentation: Harnessing LangChain to generate new data similar to existing datasets, aiding in training machine learning ****** and expanding data diversity.
- Text Classification: Utilizing LangChain for text categorization and sentiment analysis based on input text data.
- Text Summarization: Employing LangChain to condense and summarize extensive text into specified word limits or sentences.
- Machine Translation: Utilizing LangChain’s translation capabilities to convert text data into different languages, fostering multilingual communication and accessibility.
Implementing Retrieval Augmented Generation (RAG) using LangChain:
Let’s see a small implementation of the Retrieval search using lanchain. Before we start, make sure to install Python on your machine and have an open API key.
Following is an implementation of how to use a text file and do a Q&A using it with the help of RAG using LangChain with the explanation of the code:
First, install the following modules or packages:
pip install langchain openai chromadb tiktoken
Second, create a Folder with the following files:
- abc.txt (Text file)
- constants.py (python file for storing API key, here open AI API is being used)
- DocAnalysis.py (python file)
Third in abc.txt paste any data that you want to analyze and ask questions upon.
In the constants.py file paste the following code and paste the open AI API key inside the double quotes:
APIKEY = "<paste your openai API key here>"
In the DocAnalysis.py file paste the following code:
from langchain.chains import ConversationalRetrievalChain, RetrievalQA
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
import constants
loader = TextLoader("abc.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings(openai_api_key=constants.APIKEY)
llm = OpenAI(openai_api_key=constants.APIKEY)
docsearch = Chroma.from_documents (texts, embeddings)
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=docsearch.as_retriever())
"""
query = "what is this document about?"
print('\n\n-->', qa.run(query))
query = "Summarize the document"
print('\n\n-->', qa.run(query))
query = "What do we need to become an NLP engineer?"
print('\n\n-->', qa.run(query))
"""
query = "What are the responsibilities and salaries of an NLP engineer?"
print('\n\n-->', qa.run(query))
Code Explanation:
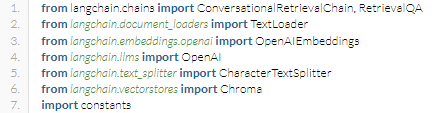
Line 1-7 imports the various functions from LangChain.
The above functions imported will be used for loading the text, analyzing it, splitting the text and measuring their relatedness, storing their relatedness in vector databases and retrieving the answers for the questions asked.

9-12 Line Loads the data or text file using the “TextLoader” function and splitting the text on separators(which is ‘\n\n’ by default) with a chunk size of 1000 and storing the split-up text into the “texts” variable.

14-17 Lines is for measuring the relatedness of text strings by creating embeddings using “OpenAIEmbeddings” with the help of an openAI API key.
18 Line is for Retrieving the embeddings created from the vector database on the “Texts” from the txt file using the “RetrievalQA” chain.

20-31 Lines are for inputting the questions/query and then running it.
some other sample questions that can be asked are commented in the code which you can uncomment and use.
Conclusion:
In conclusion, LangChain stands as a dynamic and versatile framework, empowering developers to harness the capabilities of Large Language ****** (LLMs) for a myriad of powerful applications. With its user-friendly interface and robust community support, LangChain facilitates document analysis, chatbot development, code analysis, and data augmentation, among various other tasks. Its seamless integration with text classification, summarization, and machine translation further cements its position as a fundamental tool for NLP tasks. Moreover, LangChain’s handling of embeddings and their relatedness allows for precise and nuanced data analysis, enhancing the efficiency and accuracy of various operations. With its rich set of features and modules, LangChain paves the way for innovative and impactful advancements in the field of natural language processing.