
Though a seemingly uncomplicated topic, some of the best websites struggle to create unique, high-quality content. Left unoptimized, these sites can face traffic losses and experience slow indexing and ranking speeds, depending on how widespread the issues are. Websites that seek to create unique, high-quality content should start by identifying and resolving duplication issues on their sites. In this post, we’ll cover the following:
- The meaning of duplicate content
- Why duplicate content is bad for SEO
- How to identify duplicate content
- How to handle duplicate or thin content
- What
high-quality content is
What is Duplicate Content?
Duplicate content exists when any two (or more) pages share
the same content, or almost the same content (Figure 1). Duplication can exist
on one domain, subdomains, or across multiple, unique domains.
The screenshot below is an example of what exact-match
duplication would look like across two separate URLs:

Figure 2 is an example of duplication that isn’t an exact match, as there are slight variances in the content of the two pages. Both pages, however, are ultimately targeting the same keywords and would rank for similar terms, causing duplication:
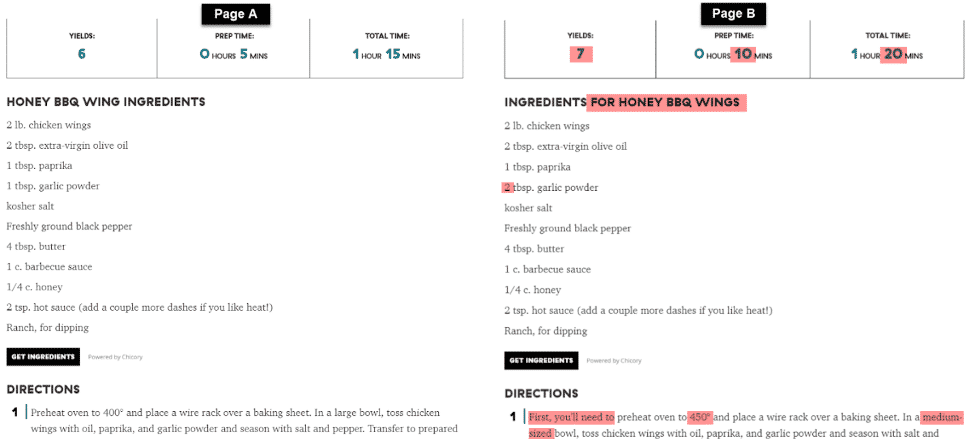
Google’s definition of duplication is “…substantive blocks of content within or across domains that either completely match other content or are appreciably similar…” You might think that two pieces of similar content wouldn’t cause much of an issue. Google has even said that there is no penalty for duplicate content. So, what’s the problem?
Why is Duplicate Content Bad for SEO?
While there is no “penalty” for having duplicate content on your site, it can hurt your organic traffic, not because Google penalizes your site, but because your rank suffers as a result of the following:
- Search engines don’t know which page to rank (you’re competing as much against yourself as with your competitors).
- This confusion can lead to two or more pages competing for rank. Sometimes multiple pages can perform relatively well for a query. In most cases, however, both pages will perform poorly, or not at all, depending on the authority of the website in the topic, for example. Having one high-quality page is going to allow for a single page to hold more equity.
- Both pages can gain backlinks.
- Simply put, backlinks are links from other sites that provide a sign of approval. They can give a URL an advantage by passing link equity and traffic from the source URL. If you have duplicate content with no variation at all (100% identical), and the less authoritative page gains backlinks, **** are you’re going to see that less authoritative page start to compete with the authoritative page, resulting in two pages splitting equity. This results in both pages performing at the same level, while one page would allow for more equity to be built up.
- Your crawl budget lacks efficiency.
- Crawl budget is the number of pages Google crawls on your site in a specific time period. This number varies from day to day and by site. Having unnecessary pages on your site, however, doesn’t allow Google to efficiently crawl your most important pages. As a result, this creates more work for Google, and could keep your new and/or authoritative pages from being crawled, indexed, and ranked in an efficient manner.
With an understanding of what duplicate content is and how it hurts your site, you might be wondering what the first step is to identify duplicate content on your site. It can often feel like a difficult task, depending on the size of your website, but it is easier if you know where to start.
Identifying Duplicate Content
There are several ways to identify duplicate content. Below are three unique methods that work well:
Finding duplication using Google Search Console (GSC) and Google Analytics
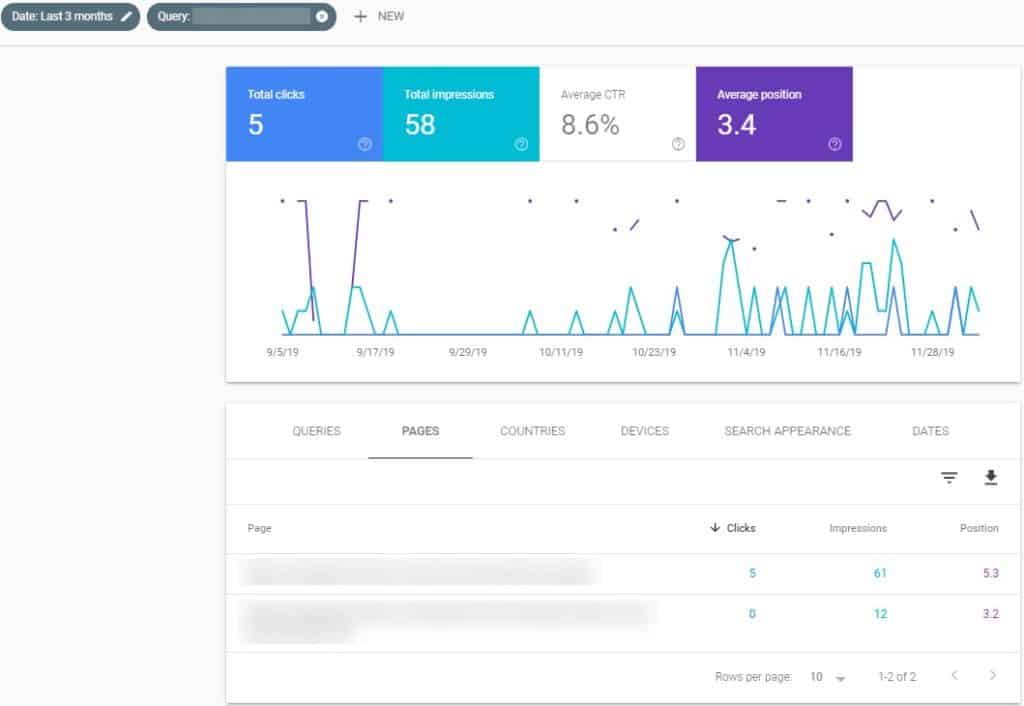
There are common URL patterns you should look for first in GSC and Google Analytics:
- http and https versions of a URL
- www and non-www versions of a URL
- URLs with a trailing slash “/” and URLs without a trailing slash
- Parameterized URLs
- Capitalization in URLs
- Canonical issues
- Auto-generated search pages
- Long-tail queries with multiple pages ranking (see screenshot in Figure 3)
Finding duplication using crawling tools
Most crawling tools can spot exact match duplication for you and assist in discovering pages with duplicate content (see Figure 4). These tools often spot the following:
- Matching H1s
- Duplicate meta descriptions and page titles
- Identical content (exact match or % similar)
After you identify duplication, you might be unsure how to manage it. Before we dive into how to handle duplication, we should note that duplicate content, according to Google, “is not grounds for action on that site unless it appears that the intent of the duplicate content is to be deceptive and manipulate search engine results.” So, in short, your website isn’t going to completely drop out of Google if you have duplication. But there is room to improve Google’s understanding of what content you want to rank, which improves organic traffic and also helps to optimize your crawl budget.
How to Handle Duplicate or Thin Content
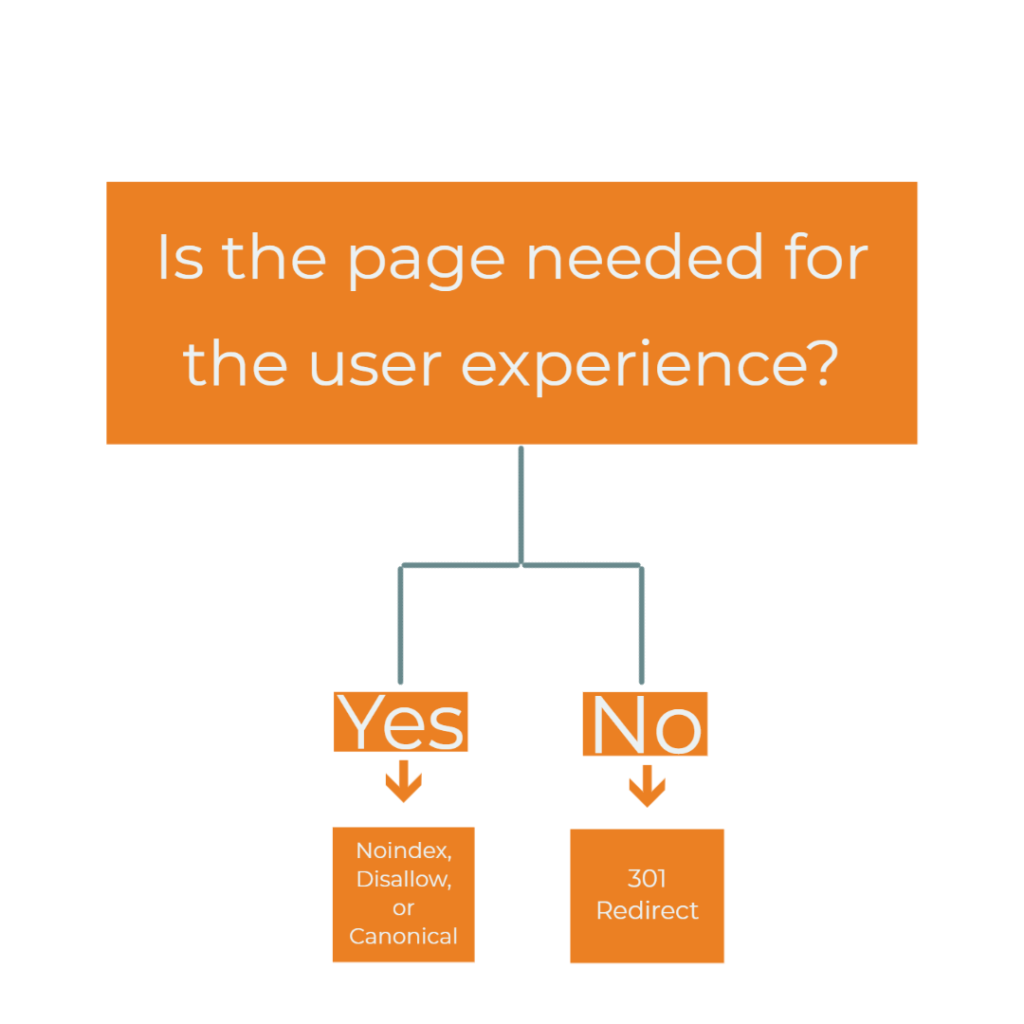
There are several ways to handle duplicate content. The method you choose ultimately comes down to whether the page is needed for user experience or not. As depicted in the flowchart in Figure 5, meta robots noindex, robots.txt disallow, or a canonical tags should be used if the page is needed for the user experience. If the page does not need to be accessed by users, a 301 redirect to the authoritative page can be put in place. It’s important to note, however, that canonicals are not respected by Google 100% of the time, unlike the other methods mentioned below.
Handling duplication with noindex
Use noindex to prevent search engines from indexing the page. Google supports two methods of noindex implementation. URLs with noindex status will be crawled less frequently, and over time, Google may even stop crawling the page altogether. However, using a noindex does not guarantee the page won’t be crawled. Google may come back and crawl the page again after the noindex is put in place, at least to verify the noindex tag is still there.
Handling duplication with disallow
Handling duplication with a disallow statement in your robots.txt file can be an easy way to handle widespread duplication. It will help optimize your crawl budget by ensuring that search engines will never crawl a certain page type. It’s important to note that using a disallow won’t remove existing URLs from Google’s index, and disallowed pages cannot pass equity.
Combining noindex and disallow?
Using a noindex tag in combination with a disallow statement in the robots.txt file is technically useless. If the URL cannot be crawled, the noindex tag cannot be seen. However it’s not uncommon to see URLs with both implementations. It is likely that the disallow statement has been added after all URLs have been de-indexed, thanks to a noindex tag previously implemented.
Handling duplication with canonical tags
Canonical tags are often used to manage duplication. If there are duplicate pages, and both pages need to exist, a canonical can be used to hint to search engines what the authoritative page should be. Note that canonicals are only hints and not directives for search engines to obey. Google does not always respect the canonical implemented by the user. In order to reinforce to search engines what an authoritative page is, a self-referencing canonical tag should be implemented on all authoritative pages, as well as making sure internal links only point to those authoritative URLs. Managing widespread duplication is often better handled with one of the methods mentioned above.
Handling duplication with a 301 redirect
Handling duplication with a 301 redirect is the most
effective method to handle duplication if the page is not needed for the user
experience. It’s important to 301 redirect the duplicative page to the
authoritative page that you want ranked. This ensures that the equity it has
built up with search engines over time will not be lost. Additionally, ensure
that you will not lose any content that is potentially unique by consolidating
content before the 301 redirect is put in place.
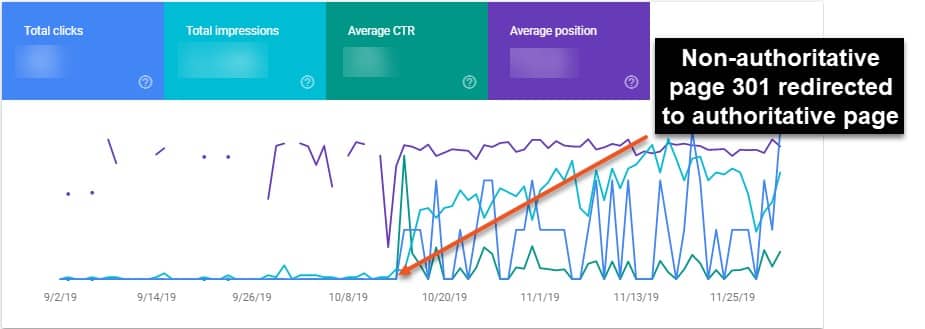
Figure 6 is a screenshot from GSC showing how an authoritative page gained traction once the non-authoritative (and duplicative) page was 301 redirected to the authoritative page and consolidated. As depicted by the inconsistent ranking and clicks, search engines had trouble understanding which page should be ranked when both pages existed on the site.
How to handle thin content
Thin content is content that is lacking in substance to the
degree that it discourages users from engaging with a website. Thin content can
hinder user experience and produce negative results in search, reducing organic
visibility opportunity. From search engines’ point of view, thin content could
mean duplicate or similar content or a low proportion of unique, crawlable page
elements. Often, a domain that contains large amounts of thin content is viewed
as a low-quality source of information by search engines. Handling thin content
also comes down to whether or not the page is needed for the user experience.
However, in most cases, including additional high-quality content on the page
is beneficial. Usually, there are opportunities to make the content unique and
to target other keywords.
Once you’ve handled duplication, and consolidated duplicate or thin content if necessary, you might be wondering what’s next. There may be opportunities to re-evaluate some of your main content to make it higher-quality. In some cases, updating content on one or both of the duplicate pages and differentiating it is a good solution for creating unique, high-quality content. With this in mind, let’s cover what high-quality content is, and what Google is looking for in your content.
What is High-Quality Content?
Let’s start this conversation in February 2011 when Google announced the Panda algorithm update.
As Google’s blog post states, this
update was made “…to reduce rankings for low-quality sites—sites which are
low-value add for users, copy content from other websites or sites that are
just not very useful. At the same time, it will provide better rankings for
high-quality sites—sites with original content and information such as
research, in-depth reports, thoughtful analysis and so on.”
This update was groundbreaking at the time, and it should not be forgotten. Many sites with the ability to rank well are missing out on traffic because their content still isn’t where it needs to be. It’s not that the site is technically wrong in any way, but the content could simply add more value to users.
Websites need to make a decision about their low-quality
content. John Mueller from Google mentions in the video below that there are
several ways to handle this. In short, he provides three ways to handle
low-quality content:
- Improve the
low-quality content, if you want to keep it. - Remove the
content completely, if it’s not something you want to stand for. - Noindex the
content, if you think it is needed for users, but you don’t want it indexed by
Google.
John says that out of all the options, Google’s ranking team prefers that you improve the quality of your content if you can.
So, what is high-quality content in Google’s eye, and what are some things you can do to improve your low-quality content?
High-quality Content is…
While there is no guarantee that content will be ranked well, high-quality content often has the following characteristics :
Unique
High-quality content is unique, meaning it provides a fresh perspective on whatever the topic is, doesn’t duplicate your site, and isn’t duplicative of another site. Sure, topics will be repeated from site to site, but there is always the opportunity to take a unique spin on a common topic to make it better. As mentioned above, you can take your duplicative content, consolidate it, and improve it to build a higher-quality and more unique piece of content to show search engines which page you want to rank.
Purposeful
Purposeful content answers users’ most difficult questions in a way that connects to your other pieces of content. Search engines gain understanding of your site by looking at how the topics are all connected.
Credible
Aim to write content that you’re an expert in. If you’re an auto parts site, don’t post content about the best vacation spots of 2020 just because there’s search volume around the topic. Some examples of creating credibility are linking to referenced expert sources, including an author with a link to the authors relevant experience, showcasing your awards and certifications in your field, or simply ensuring that page titles and main headers accurately describe the main content.
Useful
Ensure your page is useful by making it easy to understand for search engines and users. An example of this could be formatting the content in an easy-to-read format like a bulleted list. We’ve noticed that content lists with good structure are preferred by search engines, and are easier for users to understand.
Shareable
Shareable content is content that people will want to promote for you, potentially gaining valuable backlinks and driving additional traffic to your site.
Key Takeaways
- Site owners need to make a decision about their
low-quality, and duplicative content. - There are various solutions for handling
low-quality, and duplicative content depending on the situation, as discussed
above. - Ensuring your content is unique, purposeful,
credible, useful, and shareable is the best way to avoid potential losses in
traffic and issues with crawl budget.