

Foreword by Matt Diggity:
In a quick moment I’m going to hand things over to Rowan Collins, the featured guest author of this article.
Rowan is Head of Technical SEO at my agency The Search Initiative. He’s one of our best search engine technicians.
Other than being overall well-rounded search engines, Rowan is a beast when it comes to the site audit technical side of things… as you’ll soon learn.
Introduction: Rowan Collins
 Without question, the most overlooked aspect of a search engine is the site’s crawlability and indexability: the secret art of sculpting your web crawlers for the Googlebot.
Without question, the most overlooked aspect of a search engine is the site’s crawlability and indexability: the secret art of sculpting your web crawlers for the Googlebot.
If you can do it right, then you’re going to have a responsive site. Every small change can lead to big gains in the SERPs. However, if done wrong, then you’ll be left waiting weeks for an update from the Googlebot.
I’m often asked how to force Googlebot to crawl specific pages. Furthermore, people are struggling to get their pages indexed.
Well, today’s your lucky day – because that’s all about to change with this article.
I’m going to teach you the four main aspects of mastering site crawl, so you can take actionable measures to improve your site’s content standings in the SERPs.
Pillar #1: Page Blocking
Web crawlers are essential tools for the modern web. Web crawlers work uniquely, and Google assigns a “crawl budget” to each web crawler. To make sure Google is crawling the pages that you want, don’t waste that budget on a broken page.
This is where page blocking comes into play in search engine crawlers.
When it comes to blocking pages, you’ve got plenty of options, and it’s up to you which ones to use. I’m going to give you the tools, but you’ll need to conduct a site audit of your own site.
Robots.txt
Search engines use advanced algorithms to sort through millions of pages, so we can easily find what we’re looking for.
There are a variety of search engines that have proven to be promising. A simple search engine technique that I like to use is blocking pages with robots.txt.
Originally designed as a result of accidentally DDOS’ing a website with a Google’s crawler; this directive has become unofficially recognized by the web crawler.
Whilst there’s no ISO Standard for robots.txt, Googlebot does have its preferences. You can find out more about that here.
But the short version is that you can simply create a .txt file called robots, and give it directives on how to behave. You will need to structure it so that each search bots knows which search engine rules apply to itself.
Here’s an example:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://diggitymarketing.com/sitemap.xml
This is a short and sweet robots.txt file, and it’s one that you’ll likely find on your web crawler. Here it is broken down for you:
- User-Agent – this is specifying which robots should adhere to the following rules. Whilst good bots will generally follow search engine directives, bad bots do not need to.
- Disallow – this is telling the search engine bots not to crawl your /wp-admin/ folders, which is where a lot of important documents are kept for WordPress.
- Allow – this is telling the bots that despite being inside the /wp-admin/ folder, you’re still allowed to crawl this file. The admin-ajax.php file is super important, so you should keep this open for search engine bots.
- Sitemap – one of the most frequently left outlines is the submit sitemap directive. This helps Googlebot to find your XML sitemap and improve crawlability and indexability.
If you’re using Shopify then you’ll know the digital marketing hardships of not having control over your robots.txt file. Here’s what a good site structure will most likely resemble:
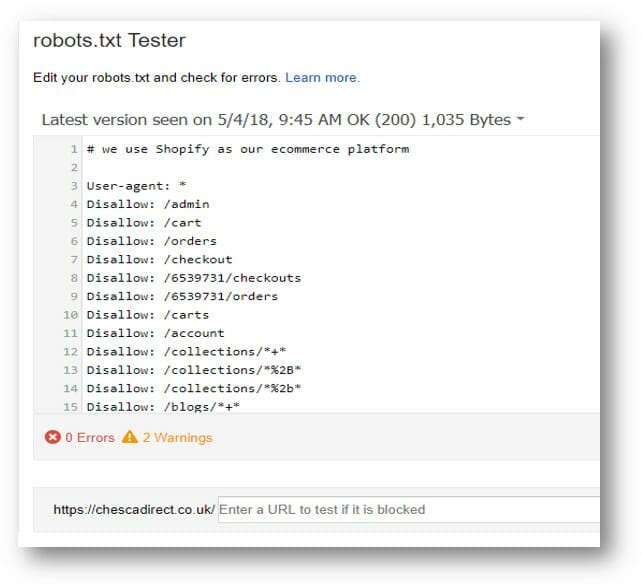
However, the following digital marketing strategy can still be applied to Shopify, and should help:
Meta Robots
Still part of the search engine bots, the meta robots tags are HTML code that can be used to specify crawl preferences.
By default all your site’s content pages will be set to index, follow links. This setting ensures that your web page is visible to search engines and that your web page has follow links – even if you don’t specify a search engine preference.
Adding this tag won’t help your page get crawled and indexed, because it’s the default. However, If you’re looking to stop your site’s crawlability and indexability of a broken page then you will need to specify.
<meta name=”robots” content=”noindex,follow”>
<meta name=”robots” content=”noindex,nofollow”>
Whilst the above two follow links tags are technically different from a robot’s directive perspective, they don’t seem to function differently according to Google.
Previously, you would specify the noindex to stop the page from being crawled. Furthermore, you would also choose to specify if the page should activate follow links.
Google recently made a statement that a noindexed broken page eventually gets treated like Soft 404s and they treat the links as nofollow. Therefore, there’s no technical difference between specifying follow links and nofollow.
However, if you don’t trust everything that John Mueller states, you can use the noindex, and follow links to specify your desire to be crawled still.
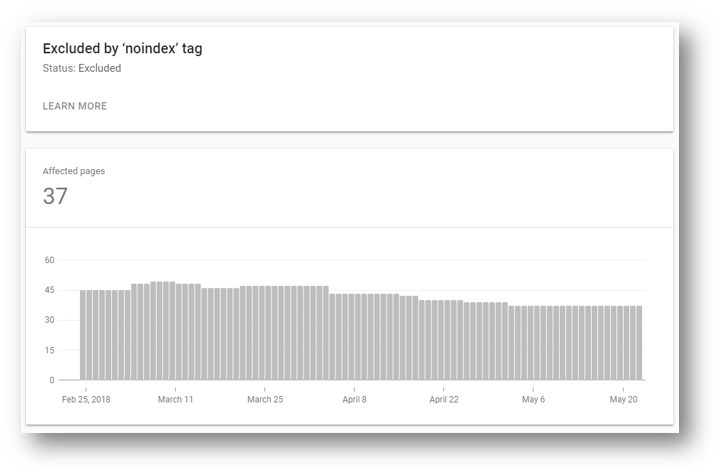
This is something that Yoast has taken on board, so you’ll notice in recent versions of the Yoast SEO plugin, the option to noindex pagination has been removed.
This is because if Googlebot is treating the noindex tag as a 404, then doing this across your pagination is an awful idea. I would stay on the side of caution and only use this for pages showing broken links, and server redirects. These are the pages you don’t want to be crawled or followed.
X-Robots Tags
Other search engines that people never really use that often include the X-Robots tags. X-robots are powerful, but not many people understand why it’s so powerful.
With the robots.txt and meta robots directives, it’s up to the robot whether it listens or not. This goes for Googlebot too, it can still ping all the pages to find out if they’re present.
Using this server header, you’re able to tell robots not to crawl your entire website from the server. This means that they won’t have a choice in the matter, they’ll simply be denied web crawle access.
This can either be done by PHP or by Apache Directives because both are processed server-side. With the .htaccess being the preferred method for blocking specific file types and PHP for specific pages.
PHP Code
Here’s an example of the code that you would use for blocking off a broken page with PHP. It’s simple, but it will be processed server-side instead of being optional for google’s crawlers.
header(“X-Robots-Tag: noindex”, true);
Apache Directive
Here’s an example of the code that you could use for blocking off .doc and .pdf files from the SERPs without having to specify every PDF in your robots.txt file.
<FilesMatch “.(doc|pdf)$”>
Header set X-Robots-Tag “noindex, noarchive, nosnippet”
</FilesMatch>
Pillar #2: Understanding Crawl Behaviours
Many of the people who follow The Lab will know that there are lots of ways that robots can act as your web crawlers. However, here’s the rundown on how it all works:
Crawl Budget
When it comes to crawl budget, this is something that only exists in principle, but not in practice. This means that there’s no way to artificially inflate your crawl budget.
For those unfamiliar, this is how much time Google web crawler will spend on your site. Megastores with 1000s of products will be crawled more extensively than those with a microsite. However, the microsite will have core pages crawled more often.
If you are having trouble getting the Google search engine to crawl your important pages, there’s probably a reason for this. Either it’s been blocked off, or it is low value.
Rather than trying to force crawls on pages, you may need to address the root of the problem.
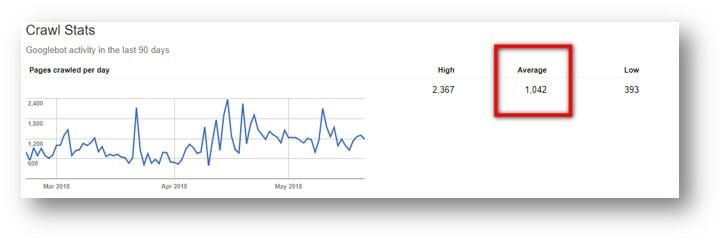
However, for those that like a rough idea, you can check the average crawl rate of your site structure in Google Search Console > Crawl Stats.
Depth First Crawling
One way that search engine bots can act as web crawlers on your web page is through the principle of depth-first. This will force google’s crawler to go as deep as possible before returning up the hierarchy.
This is an effective way for web crawlers to perform their role if you’re looking to find and strengthen internal links with relevant content in as short a time as possible.
An effective internal link structure helps website visitors navigate easily to find the search results they are looking for, as well as helps search engines understand the relevant content of the website. Internal link structure also helps to build page authority, which can result in better rankings for your pages.
However, core navigational website pages will be pushed down to the search results page.
Being aware that Google’s crawler can behave in this way will help when monitoring your website pages, including doing a site audit of your site’s internal link structure.
Breadth First Crawling
This is the opposite of depth-first crawling, in that it preserves site structure. It will start by crawling every Level 1 page before crawling every Level 2 page.
The benefit of this type of web crawler is that it will likely discover more unique URLs in a shorter period. This is because it travels across multiple categories in your website while overlooking old or deleted URLs.
So, rather than digging deep into the rabbit hole, this method seeks to find every rabbit hole before a site audit.
However, whilst this is good for preserving site architecture, it’s can be slow if your category website pages take a long time to respond and load.
Efficiency Crawling
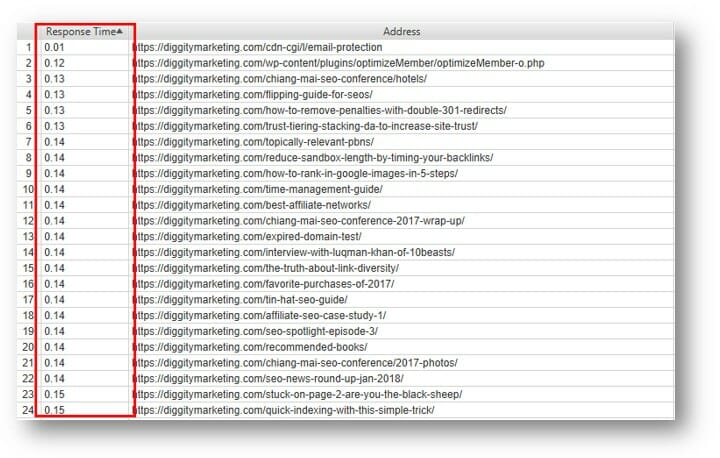
There are many different ways of crawling, but the most notable are the two above, and the third is efficiency crawling. This is where Google’s crawler doesn’t observe breadth or depth first but instead based on response times.
This means that if your web crawlers have an hour to crawl, they will pick all the website pages with low response time. This way, it’s likely to crawl a larger amount of sites in a shorter period of time. This is where the term ‘crawl budget’ comes from.
Essentially, you’re trying to make your website respond as quickly as possible. You do this so that more website pages can be crawled in that allocated time frame.
Server Speed
Many people don’t recognize that the internet is physically connected. There are millions of devices connected across the globe to share and pass files.
However, your website is being hosted on a server somewhere. For Google and your users to open your web page, this will require a connection with your server.
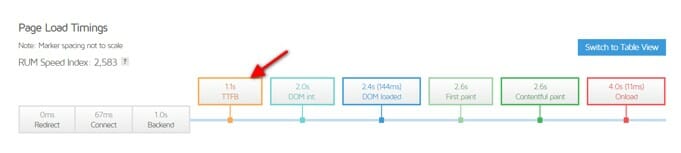
The faster your server is, the less time that Googlebot has to wait for the important files. If we review the above section about efficiency crawling; it’s clear that the log file analyzer is quite important.
When it comes to search engine ability, it pays to get good quality hosting in a location near your target audience. This will lower the latency and also wait time for each file. However, if you want to distribute internationally, you may wish to use a CDN.
Content Distribution Networks (CDNs)
Since the Googlebot search engine is crawling from the Google servers, these may be physically very far away from your website’s server. This means that Google can see your web crawlers as slow, despite your users perceiving this as a fast web page.
One way to work around this is by setting up a relevant page’s Content Distribution Network.
There are loads to choose from, but it’s really straightforward. You are paying for web crawlers to distribute your page’s content across the internet’s network.
That’s what it does, but many people ask why would web crawlers help.
If web crawlers distribute your website page’s content across the internet, the physical distance between your end user and the files can be reduced. This is the content that people see on the search results page.
This ultimately means that there’s less latency and faster load times for all of your search results pages.
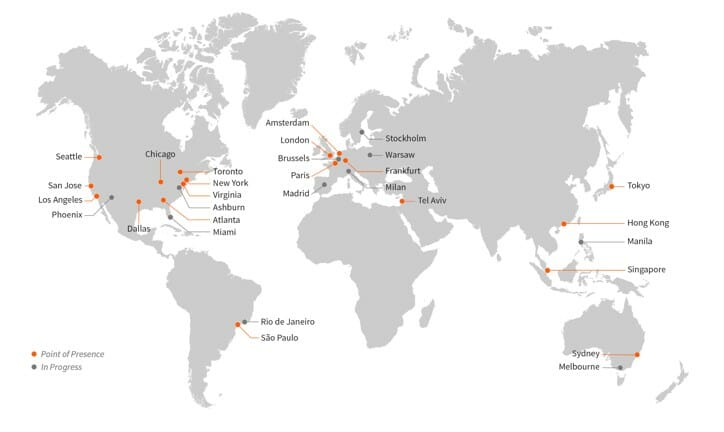
Image Credit: MaxCDN
Pillar #3: Page Funnelling
Once you understand the above and crawl bot behaviors, the next question should be; how can I force the Google search engine to crawl the website pages that I want?
Below you’re going to find some great tips on tying up loose ends on your website, funneling authority, and heightening your web crawlers.
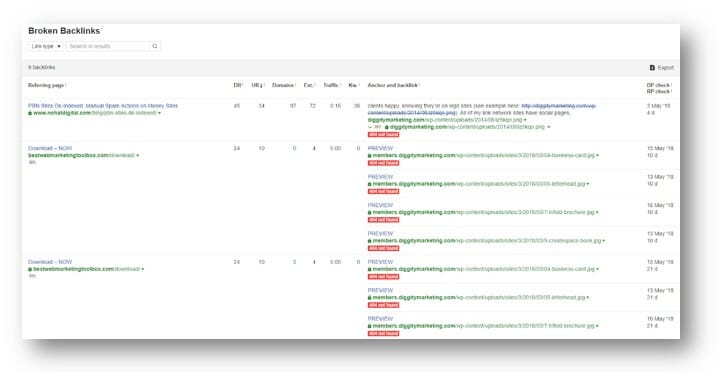
AHREFS Broken Links
Broken links can be a major problem when it comes to web page usability and search engine optimization. They can influence what’s displayed on the search results page.
At the start of every campaign, it’s essential to tie up any loose internal links. To do this, we look for any broken server redirects that are picked up in AHREFS.
Not only will this help to funnel authority through to your website; it will show broken server redirects that have been picked up. This will help the web crawlers to clean up any unintended 404s that are still live across the internet.
If you want to clean this up quickly, you can export a list of broken server redirects and then import them all to your favorite redirect plugin. We personally use Redirection and Simple 301 Redirects for our WordPress redirects.
Whilst Redirection includes import/export CSV by default, you will need to get an additional add-on for Simple 301 Redirects. It’s called bulk update and is also for free.
Screaming Frog Broken Links
Similar to above, with Screaming Frog we’re first looking to export all the 404 server errors and then add redirects. This should move all your errors into 301 redirects.
The next step to clean up your website is to strengthen internal links. Internal links can boost your website’s search engine rankings
Whilst a 301 can pass authority and relevant internal links signals, it’s normally faster and more efficient if your server isn’t processing lots of redirects. Get in the habit of cleaning up your links, and remember to optimize those anchors!

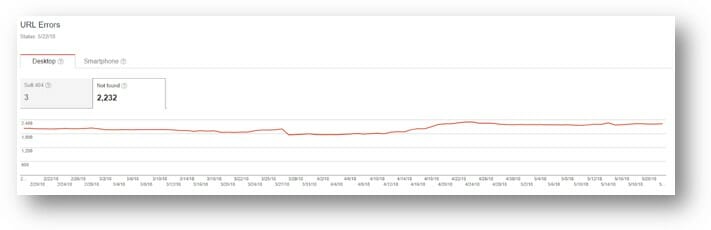
Search Console Crawl Errors
Another place you can find some errors to funnel is in your Google Search Console. This can be a handy way to find which errors Googlebot has picked up and differentiate them from relevant keywords.
Then do as you have above, export them all to csv, and bulk import the redirections. This will fix almost all your 404 errors in a couple of days. Then Googlebot will spend more time crawling your relevant website pages, and less time on your broken pages.
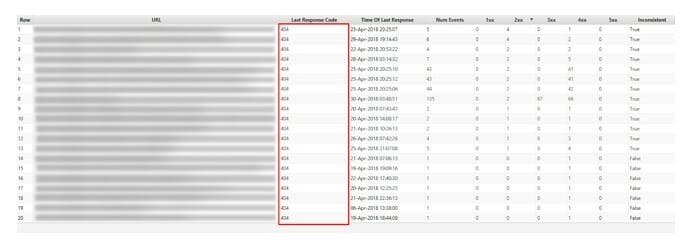
Server Log Analysis
Log file analyzer is key to unlocking the full performance of your operations! With Log File Analyzer, even the most complex data can be easily analyzed and visualized to help glean actionable insights.
Whilst all of the above tools are useful, they’re not the absolute best way to check for inefficiency. By choosing to view server logs through Screaming Frog Log File Analyzer you can find all the errors your server has picked up.
Screaming Frog filters out normal users and focuses primarily on search engine bots. This seems like it would provide the same results as above, but it’s normally more detailed and with relevant keywords.
Not only does it include each of Google’s crawlers; but you can also pick up other search engines such as Bing and Yandex. Plus since it’s every search engine error that your server picked up – you’re not going to rely on Google Search Console to be accurate.
Internal Linking
Internal links can make a difference in the performance of your website.
One way you can improve the crawl rate of a specific search results page is to strengthen internal links. It’s a simple one, but you can improve your current approach.
Using the Screaming File Log File Analyzer from above, you can see which pages are getting the most hits from Googlebot. If it’s being crawled regularly throughout the month; there’s a good chance that you’ve found a candidate for internal linking.
This page can have links added to other core posts, and this is going to help get Googlebot to the right areas of your web crawlers.
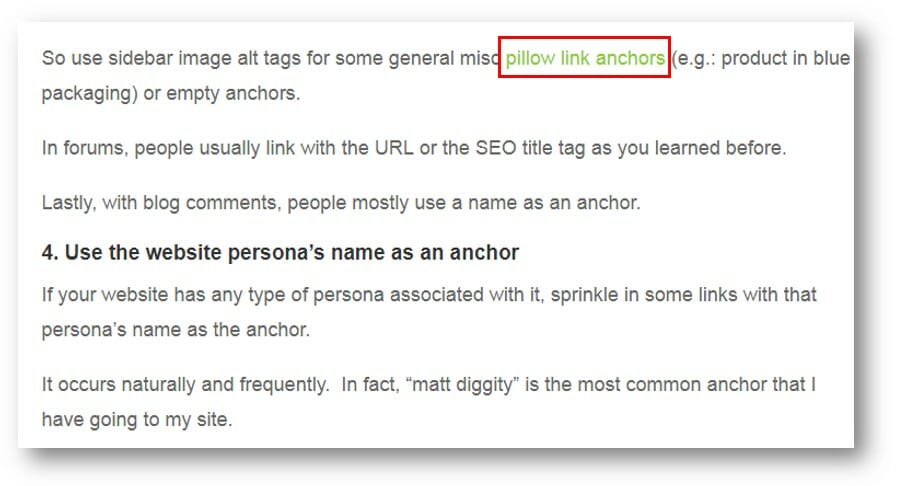
You can see below an example of how Matt endeavors to strengthen internal links regularly. This helps you guys to find more awesome web content on the search results page, and also helps Googlebot to rank his site.
Internal links are great for improving user experience and boosting your search results page rankings.
Pillar #4: Forcing a Crawl
If Googlebot is performing a site crawl and not finding your core pages, this is normally a big issue. Or if your website is too big and they’re not able to index your site – this can hurt your search engines.
Search engines do not react positively to this behavior and it can lead to a sudden drop in your website’s ranking. However, Search engines algorithm are designed to reward websites with timely, relevant, and up-to-**** content, and a forced crawl can generate outdated or irrelevant content
Thankfully, site audits can help you force a crawl on your website. However, first, there are some words of warning about this approach:
If the web crawlers are not crawling your website regularly, there’s normally a good reason for this. The most likely cause is that Google doesn’t think your website is valuable.
Another good reason for your poor website crawlability and indexability is the website is bloated. If you are struggling to get millions of pages indexed; your problem is the millions of pages with relevant keywords and not the fact that it’s not indexed.
At our search engine optimization Agency The Search Initiative, we have seen examples of websites that were spared a Panda penalty because their website crawlability and indexability was too bad for Google to find the thin web content pages. If we first fixed the site’s crawl ability and indexability issue without fixing the thin web content – we would have ended up slapped with a penalty.
It’s important to fix all of your website’s problems if you want to enjoy long lasting rankings.
Sitemap.xml
Seems like a pretty obvious one, but since Google uses XML Sitemaps as your site’s web crawlers, the first method would be to submit sitemap.
Simply take all the URLs you want indexed, then run through the list mode of Screaming Frog, by selecting List from the menu to submit sitemap:
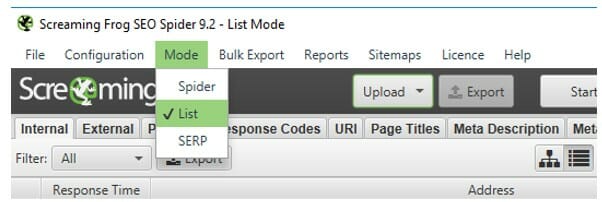
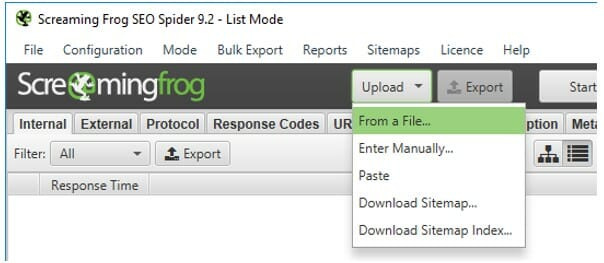
Then you can upload your URLs from one of the following options in the dropdown:
- From File
- Enter Manually
- Paste
- Download Sitemap
- Download Sitemap Index
Then once you’ve enhanced your website crawlability and indexability, ensuring all the URLs you want are indexed, you can just use the submit Sitemap feature to generate an XML Sitemap.
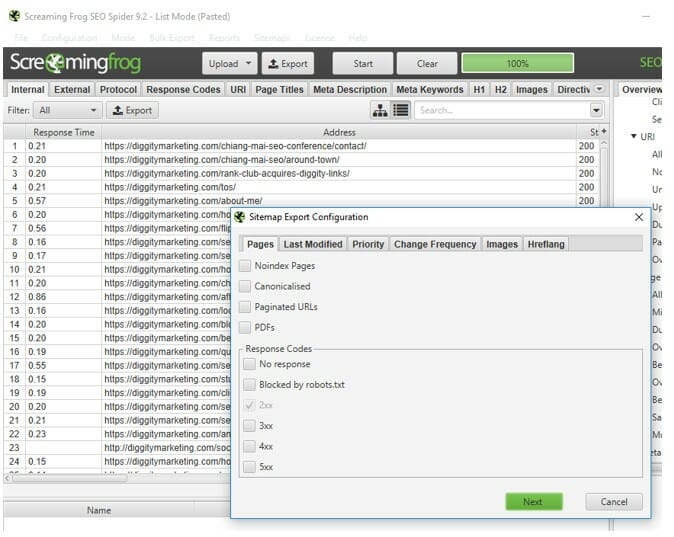
Submit this to your root directory and then upload it to Google Search engines to quickly remove any duplicate pages or pages not responsive to the website’s crawlability.
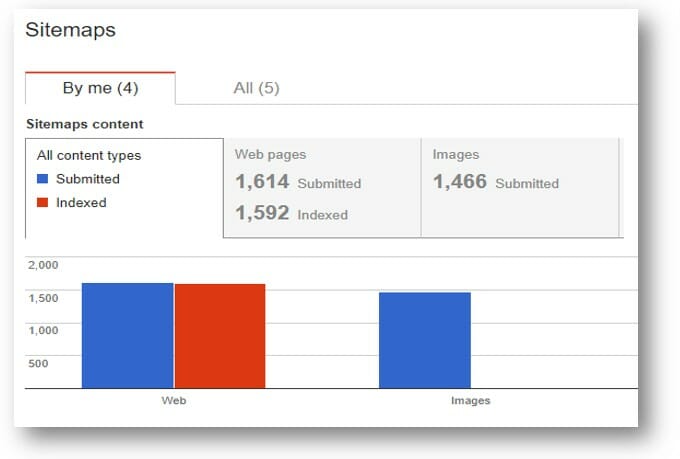
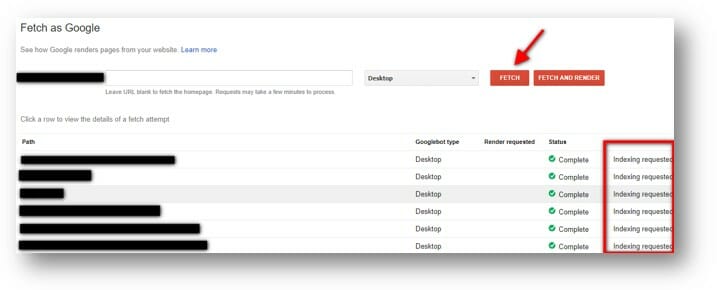
Fetch & Request Indexing
If you only have a small number of pages that you want to index, then using the Fetch and Request Indexing tool is super useful.
It works great when combined with the sitemap submissions to effectively recrawl your site in short periods of time. There’s not much to say, other than you can find it in Google Search Console > Crawl > Fetch as Google.
Link Building
It makes sense that if you are trying to have a page become more visible and powerful website’s crawlability; throwing some direct links will help you out.
Normally 1 – 2 decent direct links can help put your page on the map. This is because Google will be crawling another page and then discover the anchor towards yours. Leaving Googlebot no choice but to initiate your website’s crawlability.
Using low-quality pillow links can also work, but I would recommend that you aim for some high quality direct links. It’s ultimately going to improve your likelihood of being crawled as the good quality web content boosts your website’s crawlability.
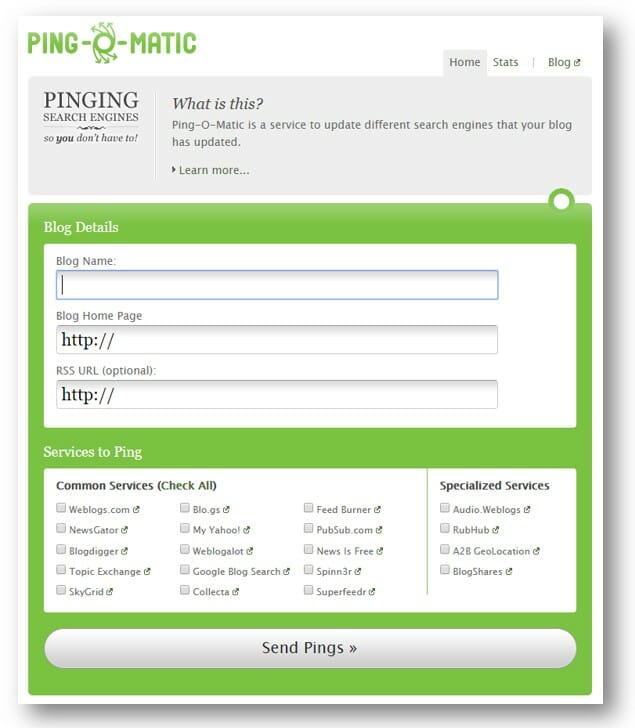
Indexing Tools
By the time you’ve got to using indexing tools, you should probably have used relevant keywords and running out of ideas.
Site audits can help you determine if your pages are good quality. If your site pages are indexable, in your sitemap, fetched and requested, with some external direct links and you’ve still not been indexed – there’s another trick you can try.
Many people use site audit indexing tools as the shortcut and default straight to it, but in most cases, it’s a waste of money. The results are often unreliable, and if you’ve done everything else right then you shouldn’t really have a problem.
However, you can use site audit tools such as Lightspeed Indexer to try and boost your website’s crawlability. There are tons of others, and they all have their unique benefits.
Most of these tools work by sending Pings to Search Engines, similar to Pingomatic.
Summary
When it comes to your site engine crawlers, there are tons of different ways to solve any problem that you face. The trick for long-term success will be figuring out which approach is best for your website’s search engine crawlers requirements through a web audit.
My advice to each individual would be this:
Make an effort to understand the basic construction and interconnectivity of the internet.
Without this foundation, the rest of the search engine’s ability becomes a series of magic tricks. However, if you are successful, then everything else about the search engine’s ability becomes demystified.
Try to remember that the algorithm is largely mathematical. Therefore, even your web content can be understood by a series of simple equations, such as direct links.
With this in mind, good luck in fixing your web crawler access issues and if you’re still having problems, you know where to find us: The Search Engines Initiative.
