
Posted by
Shay Harel
TF*IDF for SEO… depending on who you talk to it’s either the most over-hyped thing in Search since the last over-hyped thing in Search or it’s a great way to boost your SEO efforts.
What I’d like to do here is take a look at both sides of the argument and show you how you can use TF*IDF analysis for your benefit in a legitimate way… all while highlighting Rank Ranger’s new TF*IDF tool!
Sounds like a plan to me!

What is TF*IDF?
Let’s start with the most basic question of all, what is TF*IDF?
TF*IDF (term frequency*inverse document frequency), fundamentally, has nothing to do with SEO or search engines or what have you. The construct, as we pretty much know it now, came from Karen Sparck Jones, a British computer scientist, in 1972. Since then, TF*IDF has been a fundamental part of both information retrieval and text mining.
What TF*IDF does is determine how frequently a term is used within a document (hence TF or term frequency). The obvious problem is that in almost any corpus of text the words and, the, or, and the like will be the most frequently used terms and knowing their frequency is entirely pointless.
Enter the ‘IDF’. Inverse document frequency (IDF) works to discount the value of words like and, the, or, and the like. Words that appear in voluminous fashion within a document and across other documents will be discounted (with these words being and, the, or, and the like). This perfect balance of TF and IDF leaves us with the most utilized (and perhaps therefore important words) without the chaff that are words like and, the, or, etc.
For SEO purposes, TF*IDF could indicate how valuable or important a certain word or phrase is to a search engine. That is, by analyzing the top results for a given query you could conceivably arrive at the most frequently used and therefore important words that are not are, the, or, and the like.
You can see where this is heading and why there is a voice within the SEO world that discounts TF*IDF analysis.
Is TF*IDF Relevant to SEO?
When it comes to TF*IDF vis-a-vis SEO there is a bit of a pink elephant in the room. While many in the industry have embraced the idea of using TF*IDF to determine keyword relevancy there has been a strong voice of dissent from within the SEO community as well.
So who is right… those who believe TF*IDF is an amazing “SEO tool” or those who think that TF*IDF is an overblown bunch of….?
I’m going to pull an SEO cliche on you by saying… it depends.
First and foremost… TF*IDF is not an SEO tool in and of itself. It’s a method used by search engines to analyze a document in order to see what wording and concepts are most important to that document!
TF*IDF is a statistical method that can tell a search engine the importance of a word used on a page may be to the corpus that page exists in. It is not a semantic analysis tool nor SEO Tool. It is a tool that a search engine with access to its own corpus information can use.
— Bill Slawski ⚓ (@bill_slawski) July 5, 2019
Not only that, but it’s very likely, that Google has moved on from TF*IDF in favor of “more advanced pastures” via the use of a variety of machine learning properties. As far as natural language processing (NLP) goes, TF*IDF is a bit… basic (certainly in comparison to things like BERT).
Of course, using a TF*IDF tool to find the magic number of times you should use a keyword on a specific page is nonsensical. That said, there is a real way you can use a TF*IDF based analysis to your benefit, and that’s as a content tool. If we look at TF*IDF as a means towards expanding how we see our terminology choices or as a way to hone in on a page’s core identity or even as a method of surveying a competitor’s content patterns… TF*IDF is very useful.
How to use TF*IDF Data in the Modern Era of SEO
For starters, it’s not about the score per se. Even if Google were to use TF*IDF at this stage of the game, its corpus of documents stretches from here to the moon. Anything you’re going to look at is very limited and therefore any analysis you do needs to be nuanced. In other words, you simply can’t plug a URL and a keyword into our tool (or any other such tool) and use the figures shown as a ‘be-all-end-all’. You need to take the data shown within the TF*IDF tool and add a touch of qualitative analysis for it to be valuable (no matter what anyone else will tell you).
Here are some basic, as well as some more creative ways, you can use TF*IDF analysis to genuinely, boost your SEO efforts:
Avoid Keyword Stuffing
This is an obvious way you can make use of the information from a TF*IDF tool. It’s possible that the overuse of a word or phrase is what’s behind a page’s inability to rank or to rank as well as it might have otherwise. A TF*IDF based analysis can be used to quickly identify this possibility.
Take the following site for the keyword diet and health:
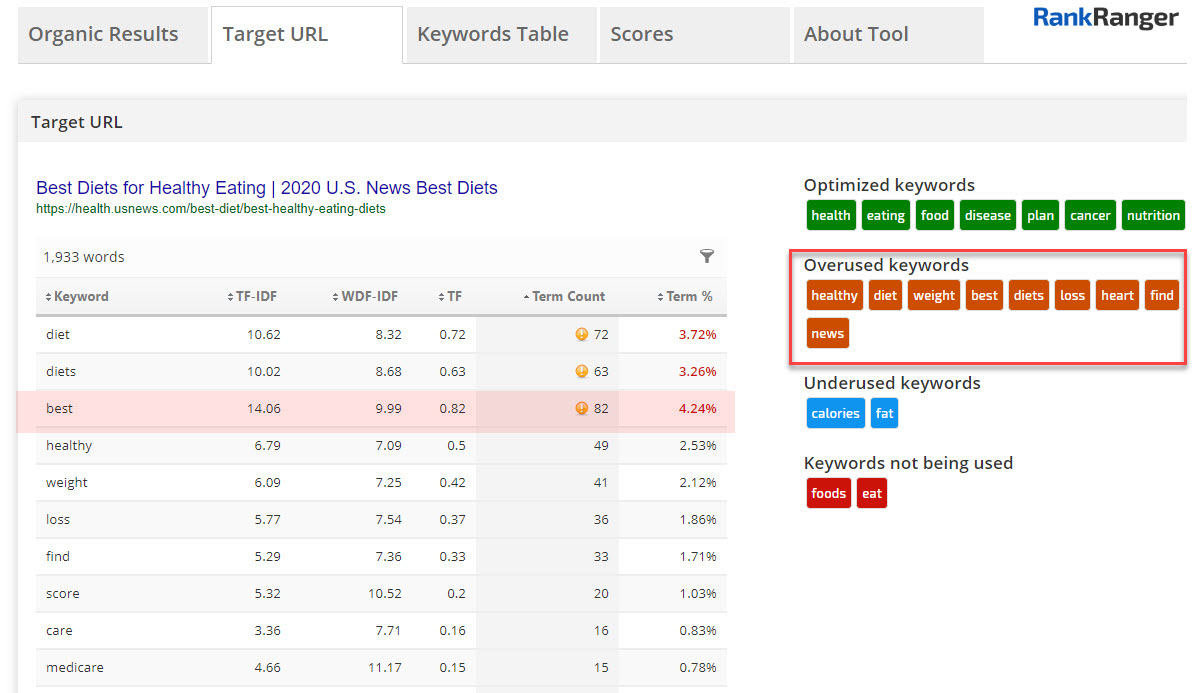
In this instance, I might not be overly concerned about the overuse of the term diet. It could simply be the page naturally makes reference to the word over the course of its development. That said, the word best is one of those cliched if not borderline spammy terms that could make a search engine wary of the page should it be overused… as it appears to be here.
Again, you can’t simply take the data from a tool like ours and say, “Oh, there’s keyword stuffing going on here.” You have to apply the ol’ brain just a bit. Still, having a TF*IDF analysis can make such an evaluation much easier than it would be otherwise.
Stay True to Page’s Core Identity
One of the major themes I’ve seen emerge from Google’s core updates are sites with conflicting identities being hurt in the rankings. In fact, one of the possible patterns I saw during the January 2020 Core Update was that pages that did not stick to their core purpose may have seen a ranking loss. That is, pages, landing pages in particular, that included content that did not align to the page’s core purpose or where the alignment of such content was not readily clear, suffered as a result of the update. In other core updates where Google believed there was a conflict in a site’s identity, even at the granular linguistic level, such sites were negatively impacted.
Getting insight into when your page’s content may not be totally aligned to its core intent is not easy. In fact, there is no tool that will directly offer this information. However, a TF*IDF analysis can point to such instances.
Take the keyword allergy test. Here, the top-ranking site does not use the term allergist at all, not once. And that’s because there is really no reason to. When talking about the administering of the allergy test the page uses the generic term “doctor.” This makes a great deal of sense since the page’s author has no idea what type of doctor may be administering the test.
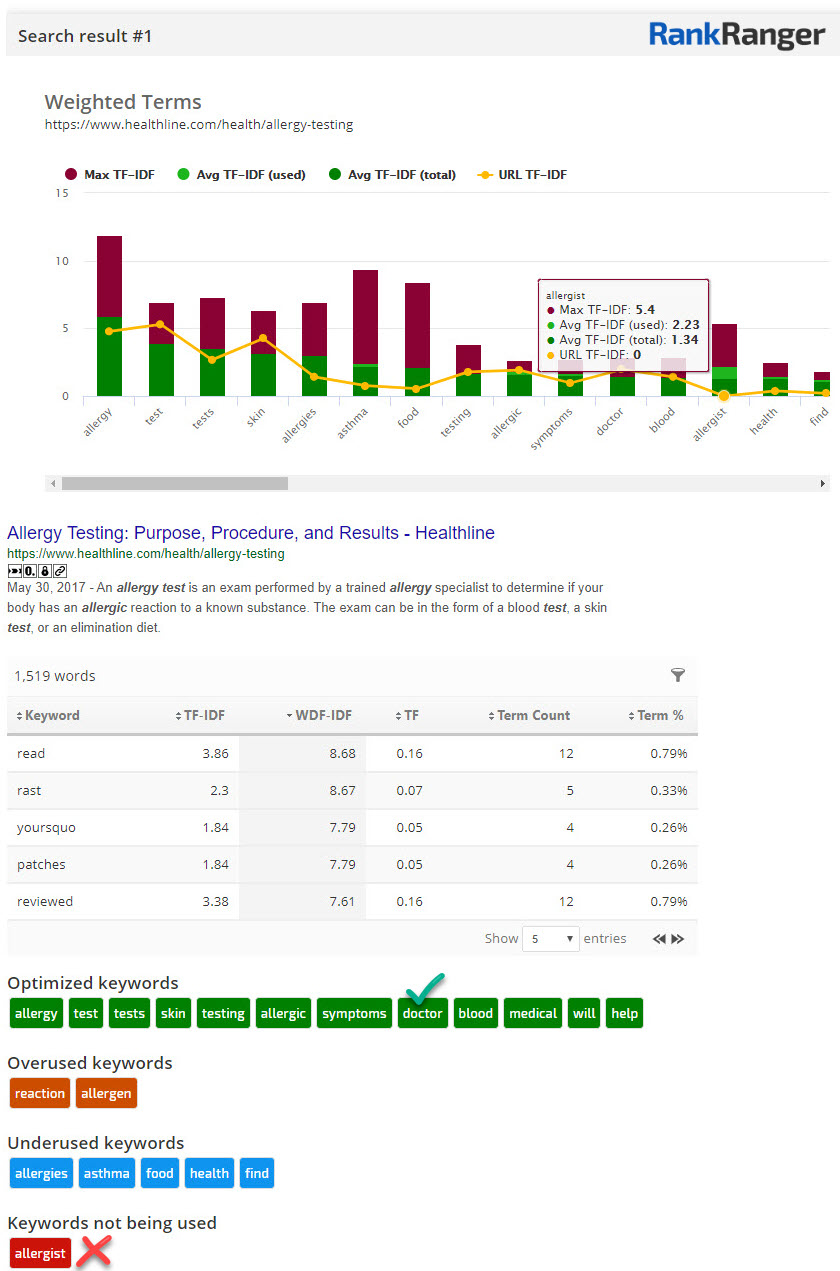
Also, any reference to they who administer the test is entirely natural and is discussed quite ‘organically’ as part of the testing process:
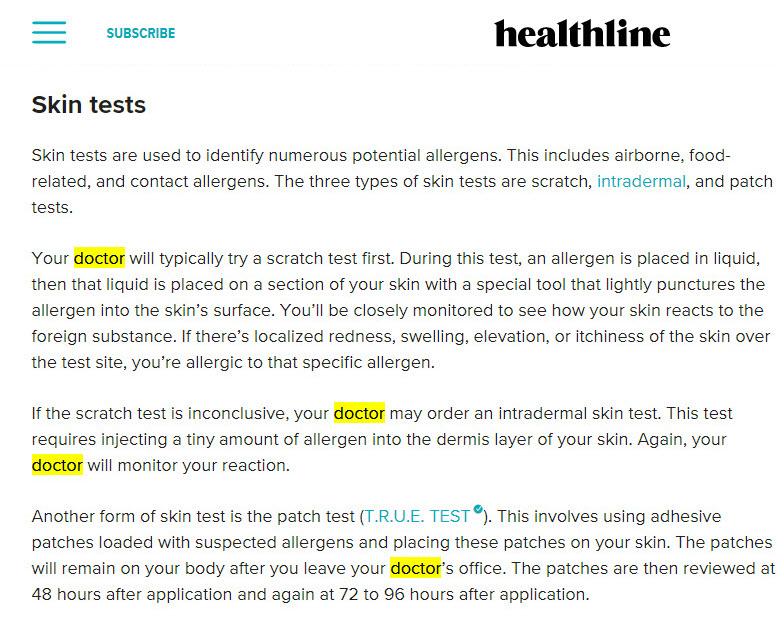
Indeed, this is the pattern for almost every page that ranks on page one of the SERP… doctor is used over allergist.
However, one web page, the 5th result for this keyword favored the term allergist.
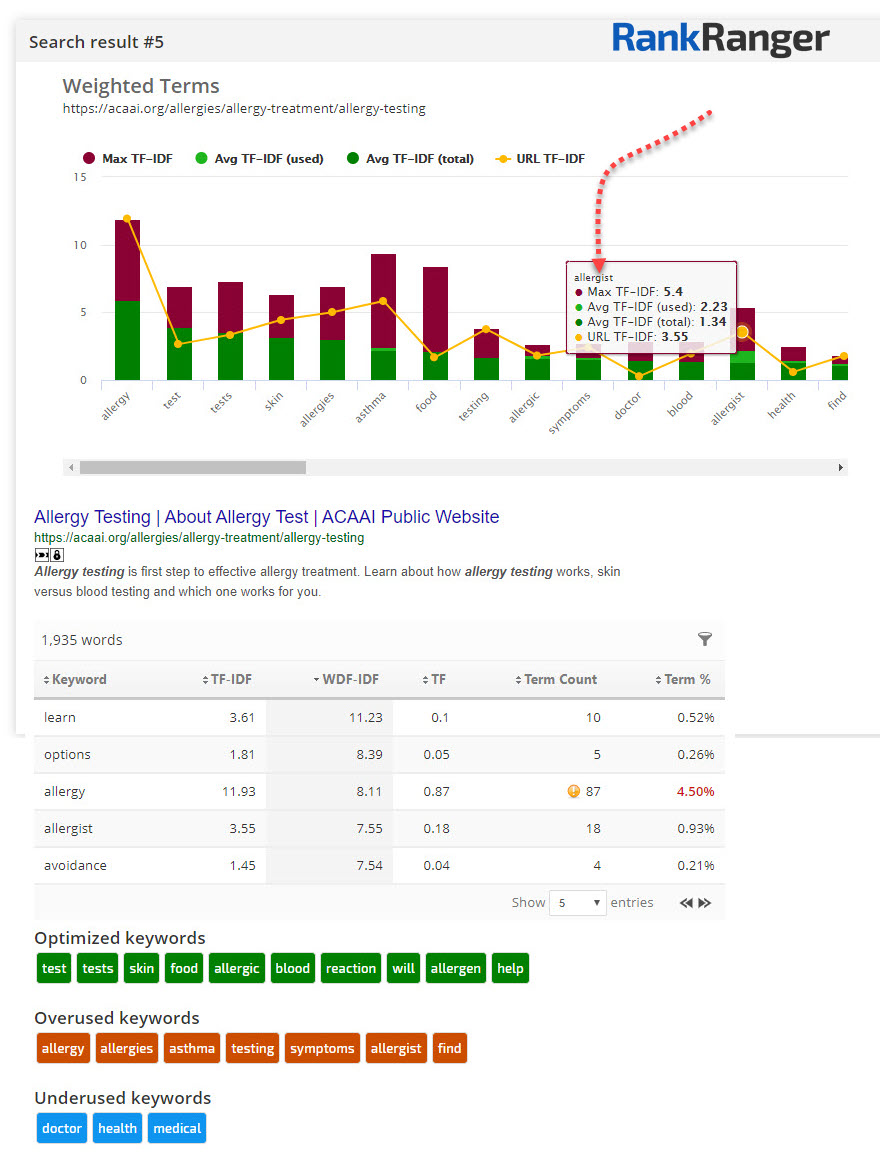
In fact, this site hardly used the phrase “doctor.” Oddly enough, this site helps you find an allergist. Thus, when discussing allergy testing it not only favors the term “allergist” over “doctor” it flaunts it:
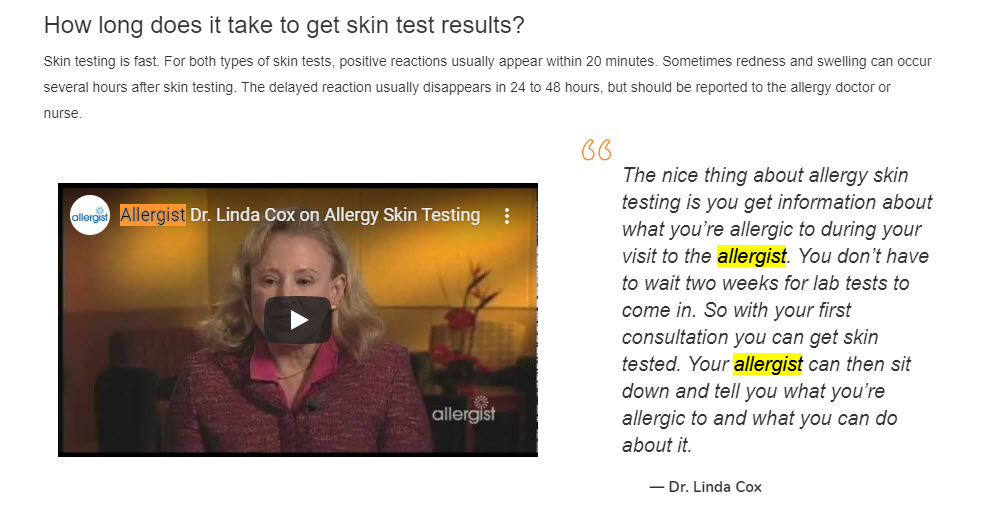
The site uses the term “allergist” to actively promote seeking one out.
That’s a lot of deep analysis there. Did TF*IDF give that to me? No. But without it, I literally would have never picked up on why this page might not be ranking as well as others on the SERP.
This is entirely my point… the TF*IDF tool didn’t give me the insight… but it gave me easy access to it once I applied a qualitative analysis!
Develop Your Content Strategy
Of all the ways to use a TF*IDF analysis in a realistic and impactful fashion, content strategy stands tall among them. There’s really a diverse set of methods towards using TF*IDF to refine and propel your content and content strategy. From real-world keyword research to competitor analysis, there’s really too much to cover here. With that, here are just a few ways to use TF*IDF from a content perspective.
Know What a Topic Consists of & What Topics to Cover
Knowing what a topic consists of, its facets and intricacies, sounds like it would be easy to uncover. Nothing a little brainstorming can’t solve. Of course, anyone who has actually tried to clearly and thoroughly concretize what a topic consists of knows its quite the challenge. For this, we often rely on more traditional keyword research tools which are great. However, if you want to get a ‘real-world’ look at what goes into a topic the TF*IDF is your friend.
By showing you what terms are being used among the top-ranking pages a TF*IDF analysis gives you a bona fide look at how the best sites approach a topic.
Take the keyword best banks, a simple TF*IDF analysis gives us a pretty good breakdown of what goes into content that takes up banking:
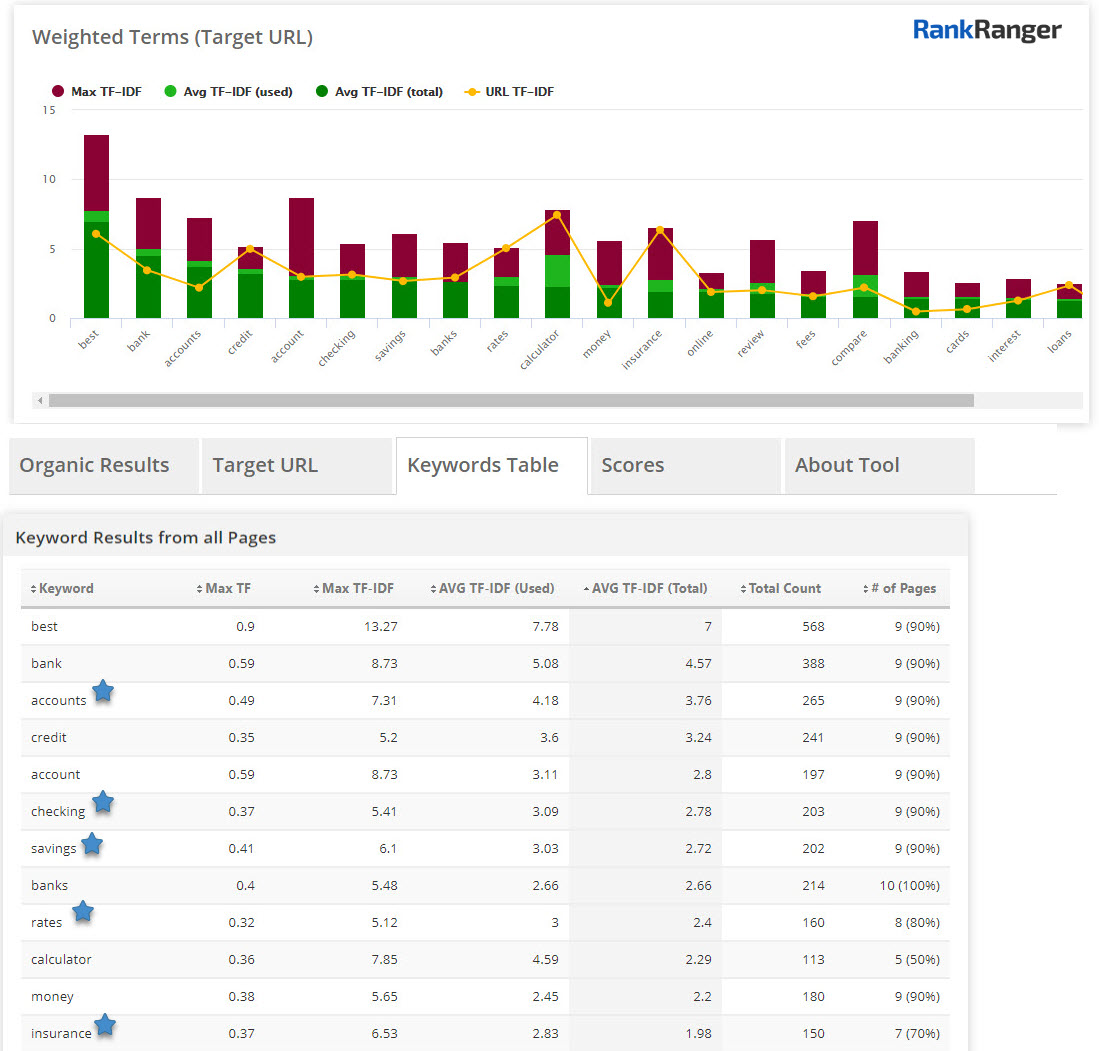
If I were to create content around finding the best bank, I would be wise to take up checking, savings, interest rates, fees, online banking, etc. Of course, a closer look at how the top sites deal with these topics is prudent… a simple glance at what a TF*IDF analysis produces helps to get a more holistic audit underway.
Close Content Gaps & Survey Competitive Practices
Similar to using TF*IDF to survey a topic, you can use the process to find any topical gaps you are not covering yourself. Here’s an example using the keyword burglar alarm:
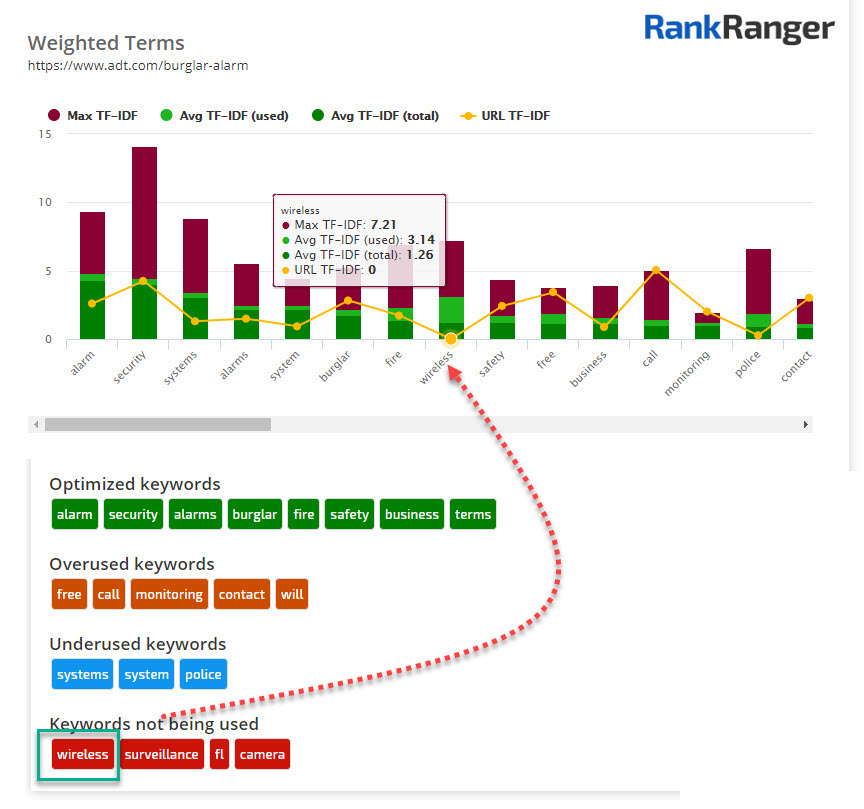
The site in question is a home alarm provider and seems to be hitting on all the right keywords.
That said, the average page featured on page one of the SERP for the keyword includes the usage of the term “wireless.” A quick survey of these sites shows that they offer a solution that does not require the installation of security alarm panels but uses some form of a wireless solution.
As such, using TF*IDF not only clues us into what aspects of a topic, or in this case a product, we may not be featuring but is a way to keep up with the competition’s content and product strategies!
Again, TF*IDF analysis doesn’t plop the answers down on your plate in one fell swoop… but with some further investigation, it puts you on the right path without much effort.
Create More Precise (and More Naturally Sounding) Content
You’re supposed to create content that sounds natural for both the sake of the user and the search engine. You’re also supposed to create the most nuanced, accurate, and precise content possible. I think we all know this at this point. However, as any writer knows… easier said than done. The language that you use and the words that you choose can set a tone that is either appropriate or inappropriate for your purposes. A more formal piece of content may rely on technical terms but should dial it back when writing on the same topic for mass consumption.
The right balance of technical terms and less formal vernacular can give your content the right tone. This is very common in industries like finance and medicine. Take the keyword Alzheimer’s medication for example. If your audience is nursing professionals you’ll use a different set of terms than you might use when writing for the average person. In the case where the latter is your target audience, you’ll probably want to make sure you’re offering great information while making it as consumable as possible. In this case, running a TF*IDF analysis might tell you that you could balance the very “cold” term treatments with a more sensitive and emotional term like care:
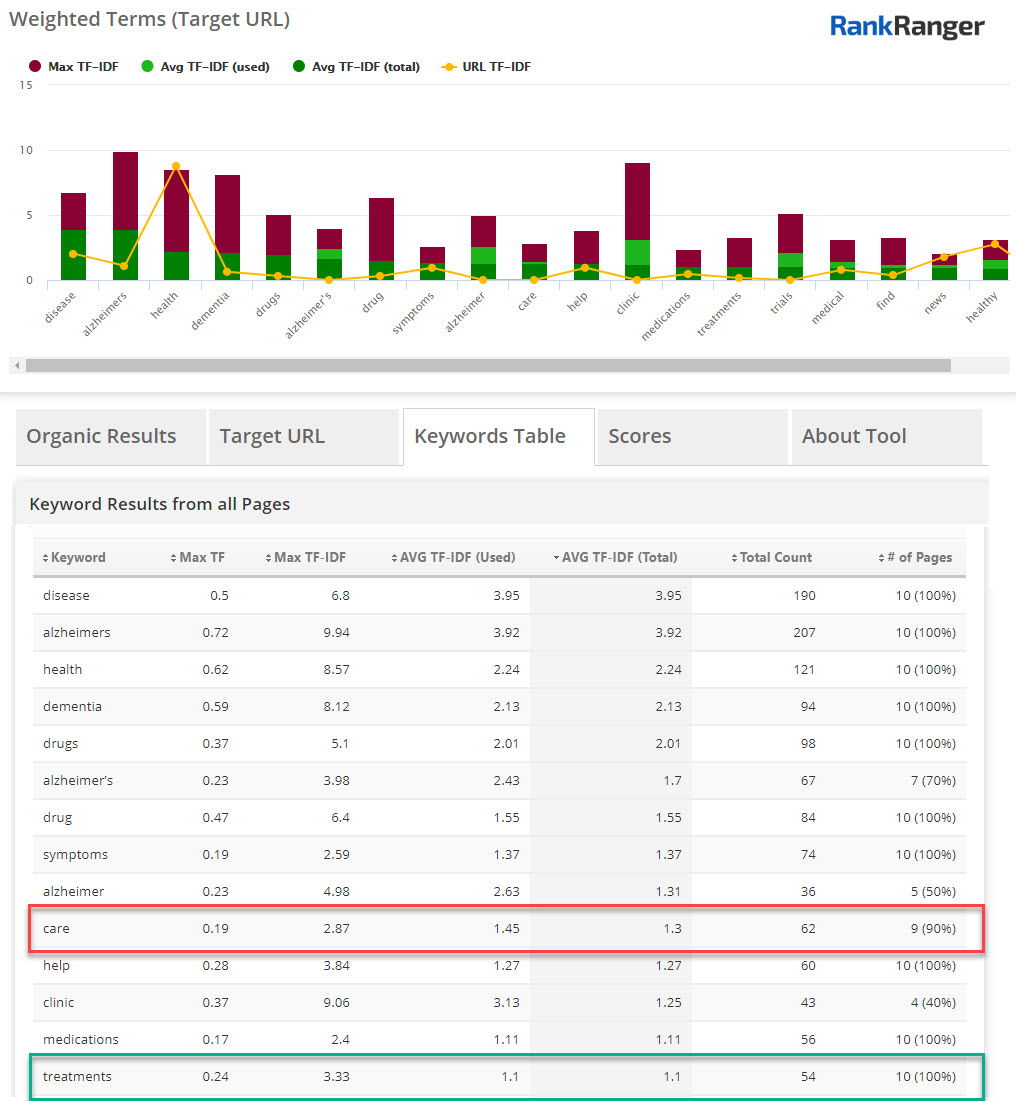
Repurpose Old Content
Just to top off the ways you can use TF*IDF to help move your content strategy forward… let’s talk repurposing old content. What you wrote about 10 years ago, the facets included, the terms you used, etc. are probably a bit divergent than what’s out there today. Running your URL through a TF*IDF analysis can help you see what terms, topics, or whatever need to be updated when you are looking to repurpose some content.
It’s not rocket science or anything, but using TF*IDF this way is a nice little timesaver that can point you in the right direction.
TF*IDF: Some Assembly Required

The idea that I’m trying to get at is that TF*IDF is not some sort of ‘top-level’ tool to get some quick and easy analysis. That’s not how to use it. That’s a very basic and pretty much irrelevant way to look at a TF*IDF analysis (for the most part).
Rather, what you get with TF*IDF is direction. What you get are signals that you can use to start your investigation. You get the insight you need to know where to start, what to look at, and how to go about a more qualitative sort of analysis.
How you use this data goes well beyond what I’ve illustrated above. It all depends on what you’re trying to accomplish, what site or vertical you’re dealing with, and a lot more. The common thread is that a TF*IDF analysis can give you a more ‘natural’ look at what actual content on the SERP looks like and sounds like.
You can find the Rank Ranger TF*IDF tool within our UI under: Reports>Audit>On-Page>TF-IDF Tool
About The Author
